服务端开发
Spring boot 开发框架
- 可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执行的JARs和WARs(不需要其他依赖直接就能跑)
- 内嵌Tomcat或Jetty等Serverlet容器(Web容器)
- 提供自动配置的starter项目对象模型以简化Maven配置(依赖集成)
- 尽可能自动配置Spring容器
- 提供准备好的特性
- 绝对没有代码生成
ObjectBeanComponent
Component更加面向业务
Bean更加抽象一点,是spring管理的一个基本单元
object面向对象语言中的对象
Jar 和 War 的区别
Jar比较大,因为它能直接跑,War里面没有Tomcat,不能直接跑
Thymeleaf 模版解析器,用于生成动态的HTML页面
没有特别指定的版本号都用parent里面对应的版本号
@SpringBootApplication
这个注解至少包括了三个注解类:
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan:Spring boot按照参数中给出的路径,针对特定的type,扫描类定义,在看到@Component注解时进行实例化
开发框架的分层
Spring的衍生
Springboot
springcloud
Junit测试用例
- 使用@Test
- 使用void进行修饰
- assert,对预期结果的断定
开发期工具:Spring boot DevTools
依赖注入
Bean的生命周期
应用上下文
- AnnotationConfigApplicationContext
- AnnotationConfigWebApplicationContext
- ClassPathXmlApplicationContext(基于xml文件建立的应用上下文)
注解配置(Recommended)
@Component但是有的类需要初始化属性,所以可以使用@Autowired(命令spring去上下文中寻找符合类型要求的对象,如果找到了并且只找到一个,那么直接注入,没找到直接失败,如果找到了多个对象也会报错 可以使用@Primary让Spring优先注入某类实例,也可以通过@Qualifier(cd【Bean的id】,这个id默认是当前类的名字,也可以通过@Component(Bean的id)来指定)来要求spring只寻找cd来注入) 这个注解可以加到属性上,也可以加到构造函数上
配置类
@Configuration 说明这是一个配置类
@ComponentScan 命令Spring去扫描当前类所在的包及自报加了@Component注解的类并实例化,也可以使用@ComponentScan(basePackages = {“soudsystem”,”abc”,…})指定想扫描的包路径(这是类型不安全的,因为都是字符串)或是@ComponentScan(basePackageClasses=CDplayer.class)让spring去指定的类所在的包下去搜索(这是类型安全的,但是面对代码重构是error pone的,为了处理,我们可以干脆在要指定的包下建立一个空接口)
通过注解配置建立上下文
1 | ApplicationContext ctx = new AnnotationConfigApplicationContent(CDplayerConfig.class); |
在测试中使用
@ContextConfiguration(classes = CDplayerConfig)
System.getProperty(“line.separator”)可以获得当前系统的换行符
XML配置
1 | <beans xml:c="spring/schema/c"> |
@ContextCOnfiguration(locations=)
javaconfig配置(实例化第三方库的时候用得到)
1 |
|
混合配制
1 |
|
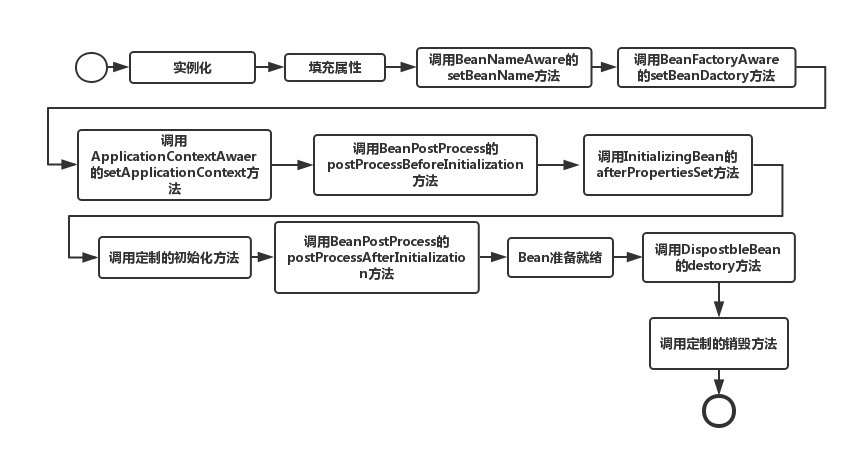
Bean的生命周期
BeanNameAware要实现setBeanName
类似的还有ApplicationContextAware,可以在它的set方法里面获得丰富的信息
Java Faker
一个专门构建测试假信息的工具
其他方法
@Profiles
根据指定的profile选择性的创建
@Conditional
根据条件选择是否创建
@ScopedBeans
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
让spring不再拦截多实例创建
制定作用域
Session 会话 为每个会话创建一个实例
Request 请求 为每个请求创建一个实例
面向切面的编程
AOP目标是解决什么问题?
- 分离横切关注点,将业务代码分离出来,避免对代码的侵入
- 减少耦合
AOP aspect Oreiented Programming
关注点
- 日志
- 安全
- 事务
- 缓存
可选
- 继承
- 委托
黑话
- 通知 advice:切面做什么以及何时(方法前?方法后?异常时)
- 切点pointcut:何处
- 切面aspect:通知和切点的结合
- 连接点join point:所有可以切的点:方法、字段修改、构造方法
- 引入introduction:引入新的行为和状态,但是不是新建子类,而是动态地新增方法
- 织入 weaving:将切面应用到目标对象
通知类型
- @Before 将逻辑切入到方法调用前
- @After …方法执行后
- @AfterReturning
- @AfterThrowing
- @Around 四合一
1 |
|
配置类
@EnableAspectJAutoProxy
是否允许被切的对象创建代理
同时要实例化切片
可以这样定义一个pointCut来简化切面
1 |
|
around的使用
1 |
|
1 | //括号里是注解类这个参数的名字 |
切片是如何实现的?
Spring通过将目标对象和切面一同打包实现一个代理对象,首先处理切面,再处理目标对象
AspectJ 切点指示器
1 | //指定方法、获取参数(捕获目标方法的参数)、限定包路径、限定bean名称 |
通过切片扩展类的行为
1 |
|
1 |
|
1 | package concert; |
1 | package concert; |
1 | Encoreable concert2 = ctx.getBean("concert2", Encoreable.class); |
横切关注点
- 日志
- 安全:比如用户权限的控制
- 事务:比如数据库事务
- 缓存:提升性能
在没有切片之前…
委托(持有一个引用)、继承
织入时机
运行期:使用代理对象,只支持方法级别的切入
MVC架构
Web开发框架分层,请求是如何被处理的
基本的层为 控制器层、业务逻辑层、数据访问层
- 请求发到基本单元Severlet
- Mapping组件根据url,将请求交给对应的控制器,同时解析参数
- Controller拿到参数,校验后交给业务层
- 业务层进行业务处理,可能与数据访问层发生交互
- 业务层将处理结果交给Controller
- Controller将结果交给Serverlet
- Severlet寻找第三方渲染库,将数据和逻辑视图名交给之
- 第三方库渲染逻辑视图
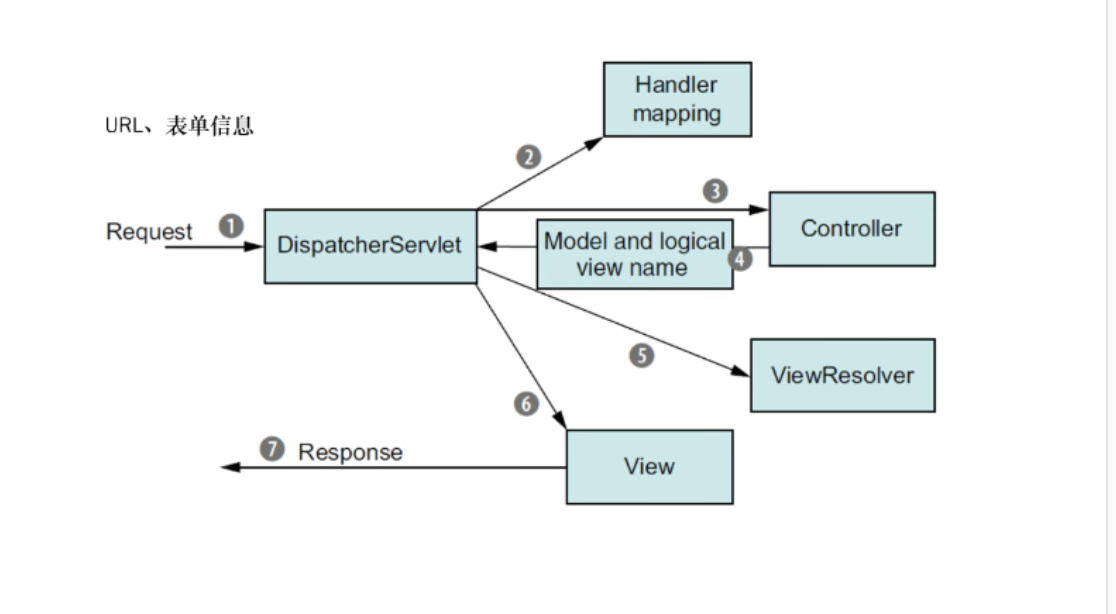
model-view-controller
模型:存储内容
控制器:处理
视图:显示内容
适用于前后端不分离的开发场景
@Data注解
没有data注解时,我们要为每个属性写get方法和set方法
加了data,lombok会帮助我们生成这些方法
lombok仅在编译时生效,我们可以在pom中设置exclude,发行版中不加入lombok包
Controller
@RequestMapping(“/design”)
让控制器处理以design为前缀的url
@Controller
告诉spring这是controller,效果上和@component一样
@GetMapping
get请求到这里处理
请求的类别
- Get 获得资源
- Post 创建资源
- Put 更新资源
- Delete 删除资源
- Patch
1 | return "design"; |
这里返回的字符串是一个逻辑视图名,spring在resource/template中找到模版,塞入数据后(渲染)出页面
@SessionAttributes(“Taco”)
指定Taco是一个Session级别的属性,一次会话包含多次请求
1 |
|
@Slf4j
定义一个log对象,让你打印log
@Valid
添加校验
校验表单输入
领域类添加校验规则
属性上方添加一些注解
1
2
3
private List<Ingredient> ingredients;添加@Valid注解
1
2
3
4
public String processTaco(
Taco taco, Errors errors,
TacoOrder tacoOrder)修改表单视图展示错误
WebConfig
1 |
|
Spring MVC获取参数的几种方式
- form参数转成model,成员类型可能会用到Converter进行类型转换
- 路径参数 @Pathvariable
- 请求参数(查询参数),
- json请求体,@RequestBody,会用到HttpMessageConverter消息转换器,RestAPI
Spring MVC的请求映射注解
可以放在类上,也可以放在方法上
@RequestMapping 可以再这个注解后面详细解释,是通用的
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
@PatchMapping
Model和View的关系
Model提供View的输入
Model属性会复制到Servlet Request属性中,给视图用于渲染页面
thymeleaf和spring mvc是解耦的
Spring MVC发现了thymeleaf,会自己帮你创建支持thymeleaf的bean
处理表单提交
校验表单输入
javaBean Validation API
spring-boot-starter-validation(Hibernate针对javaBean Validation API的实现)
领域类加校验规则
控制器中声明校验
修改表单视图展现校验错误
WebMVConfigurer
可以做很多事
服务端数据库开发
使用几大springboot数据库开发框架的基本流程
JdbcTemplate
- 配置依赖
- 配置数据源
- 注入JdbcTemplate
- 为查询创建相应的Mapper
- 使用jdbcTemplate.update,query等执行操作
Spring data
JPA,比如Hibernate
- 配置依赖
- 配置Entity实体类
- 创建继承或实现CurdRepository接口的数据库接口
- 注入这个数据库
- 使用默认提供的方法就可以做到增删改查了
三种实现方式的区别和相同点
- template和spring data都需要提供schema脚本,jpa不需要,根据java对象生成表结构
- 从实现来看,template需要我们自行实现接口,spring data和jpa在大多数情况下不用再实现
- 从领域对象来看,template领域对象不用加注解,而后两种需要
- 后两者都提供了Query,但JPA可以通过DSL语言实现灵活的query
- 关于id字段的处理,template需要主动获取新生成的id,第二种和第三种不用
- spring data的持久化注解来自spring自行定义,JPA来自javax
数据库初始化的基本方式
- schema.sql表创建,data.sql数据初始化
- 程序预加载:commandlinerunner接口,applicationrunner
基本继承的接口
curdRepository
数据库开发中基于接口交互的好处
- 便于对数据库访问层和业务逻辑层的测试,可以使用Mock工具提供接口的实现
- 可以灵活的替换数据库的实现,而不用更改业务层代码
Spring为数据库访问提供了抽象的简化
1 | private JdbcTemplate jdbcTemplate; |
这个类会被spring框架自动注入
SQLException
- 数据库连接中断
- 表不存在
- SQL语法错误
- …
JdbcTemplate
- xml中添加jdbc依赖
- 在xml中指定数据库类型(MySQL、H2、Postgresql…)
- (H2)在resources里面写.sql文件
- 写@Repository
在业务层访问Repository
JdbcOperations是JdbcTemplate实现的接口
访问H2控制台
1 | /h2-console |
添加devtools访问
data-jdbc
Spring Data项目
只是定义而不需实现接口(spring 来实现)
1
2
3
4
5
6
7
8import org.springframework.data.repository.CurdRepository;
public interface IngredientRepository extends CrudRepository<Ingredient, String> { //指明操作的对象和ID的类型
// 如果我想要添加一个新的查询方法,动作+By+字段,这是“领域特定语言”
// 如果要更具体
//方法名就叫叭叭叭ba~
List<TacoOrder> findByDeliveryZip(String DeliveryZip);
}定义数据类
1
2
3
4
5
6
7
8
9
10
11
12
13
14import lombok.Data;
import lombok.;
public class Ingredient implements Persistable<String> {
private String id;
private String name;
}注意命名规范!java驼峰与建库脚本下划线对应
根路径下添加创建表的脚本
接口注入到业务层或控制器
如果你需要启动时插入数据…
在Application入口类中建立一个内部类
1
2
3
4
5
6
7
public CommandLineRunner dataLoader(BoyRepository repo){
return args -> {
repo.deleteAll();
repo.save(new Boy())
}
}此方法调用的时机是所有Bean创建完成后,Application最后启动前
Spring Data JPA
- JPA:Java Persistence API
- 宗旨是为POJO提供持久化标准规范
- JPQL是一种面向对象的查询语言(类似SQL)
- 依赖是data-jpa
步骤
接口和上面的是一模一样嘟
对应关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//比table更厉害的注解,不要你写表结构,来自javax.persistense
public class Ingredient{
private String id;
private String cao;
//告诉spring表之间有关联,cascade意味着一旦order被删除,对应的Taco一起删除
private List<Taco> tacos = new ArrayList<>();
}
数据库初始化有三种方式
- Data.sql schema.sql文本文件初始化
- CommandLineRunner接口或ApplicationRunner接口
使用非关系型数据库
添加依赖
1 |
使用mongoDB client(不推荐)
1 | try{ |
JPA自动配置 (推荐)
propertie
1 | spring.data.mongodb.uri=mongodb://localhost:27017/test |
1 | public interface |
1 |
|
Nosql倾向于把能关联的数据都塞进去,这会造成严重的重复存储问题,这就引出一堆去除重复方法
MongoDB性能
10000条数据插入大概是10s
Java Faker
1 | public void fack(){ |
使用Redis
Redis的主要用途是缓存,我们不那么关心它是否能持久化
存储的基本单位是key-value
- redis-server
- redis配置,redis.conf
- 默认端口号6379
- redis-cli,客户端程序
redis启动后默认开16个数据库
插入key-value
1 | set myname lyl |
redis中可以给key设置生命时长
1 | expire counter 15 //15s后counter就寄了 |
key-value中value可以有不同类型,包括String(注意 前面的counter也是String,不过你还是可以加加减减的), List
1 | rpush mylist 15 //往mylist里面(不存在新建)从右边加一个15 |
Hash类型
1 | hmset user name lyl age 10 |
set
1 | sadd myset 1 2 3 |
删除数据库
1 | flushdb //删掉当前数据库 |
Jedis(早期)与Lettuce(现在)
它们都是供spring连接到redis的客户端
RedisConnectionFactory接口,JedisConnectionFactory
Application
1
2
3
4
5
6
7
// String对应key,Product可以简单理解为value(但严格并不是)
public RedisTemplate<String,Product> redisTemplate(RedisConnectFactory cf){
RedisTemplate<String, Product> redis = new RedisTemplate<>();
redis.setConnectionFactory(cf);
return redis;
}properties
1
2spring.redis.host=localhost
spring.redis.port=...1
2
3
4
5
6
7Product product = new Product();
product.setName("bababa");
product.setSku("978888")
redisTemplate.opsForVlaue().set(product.getSku(),product); //这最后存的是String类型,相当于做了序列化,也就是java提供的Serializable,字节化也就能持久化了
//这个时候去redis里面看key的内容,只会看到一坨意义不明的东西,这是序列化后的字节序列,这是JDK自己的方式
//通过
private static final long serialVersionUID = 1L;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17redisTemplate.opsForList().rightPush("cart",product1);
redisTemplate.opsForList().rightPush("cart",product2);
Product first = redisTemplate.leftPop("cart");
List<Product> products = redisTemplate.opForList().range("cart",2,12);
redisTemplate.opForSet();
//如果懒得老是指定"cart"这样的key
BoudListOperations<String,Product> cart = redisTemplate.boundListOps("cart");
//其实大家都喜欢用json格式串而不是jdk序列化
redis.setKeySerializer(new StringRedisSerializer());
redis.setValueSerializer(new Jackson2JsonRedisSerializer<Product>(Product.class));
//如果你想让redis忠实地返回数据库里的东西
stringRedisTemplate = new StringRedisTemplate(cf);
目前用到的依赖
Spring Security
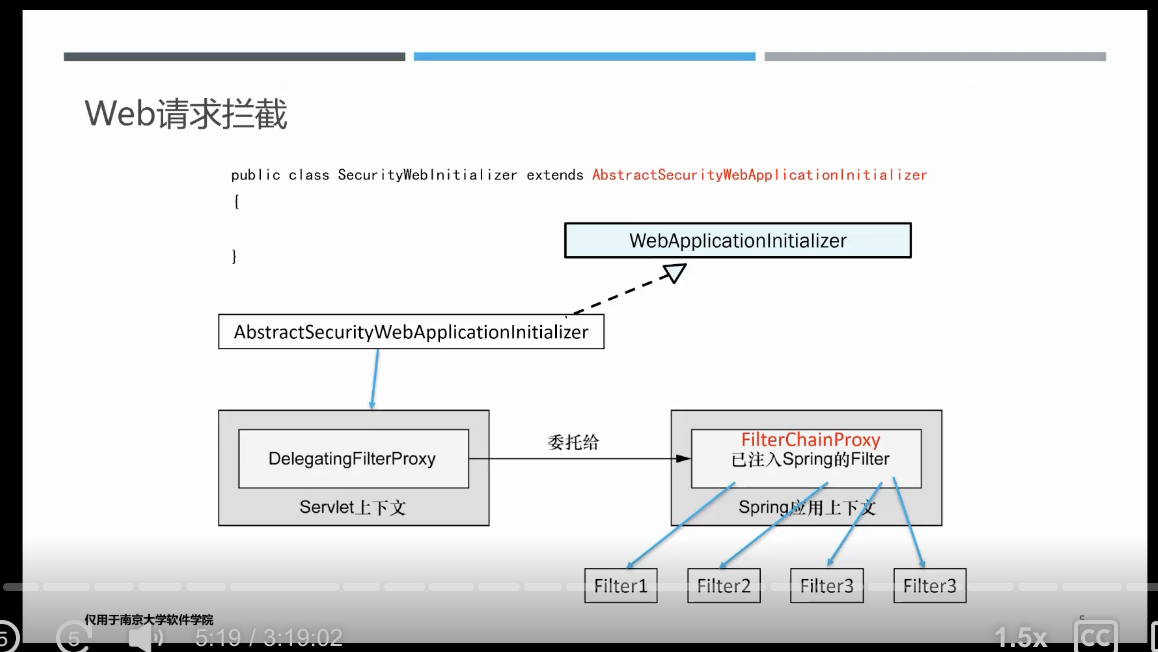
权限控制原理 filter
请求处理之前会由一系列filter进行拦截处理
开发实际操作中的步骤
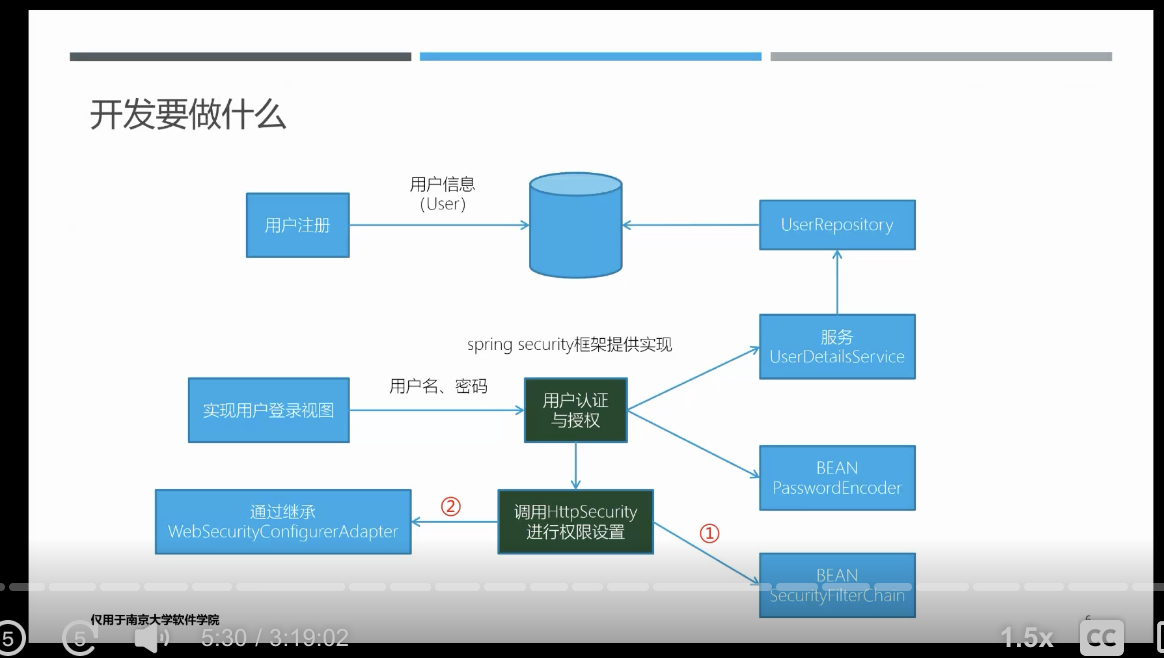
- 实现一个接口:UserDetailService
- 提供密码加解器
- 提供一个登录页面
- 使用y继承自HttpSecurity的SecurityFilterChain或WebSecurityAdapter进行权限处理
框架帮我做的
- 登录控制器的实现(Get,Post)
- 请求重定向到用户登录页面
- 通过Filter对设定的权限进行控制
用户信息的存储
- 内存用户存储
- JDBC数据库
- LDAP目录数据库
权限分类
创建自定义登录页

Basic认证
方法级的权限控制
@PreAuthorize(“hasRolr(‘USER’)”) 实现就是基于AOP
jaas:jdk用户授权框架
添加依赖:spring-boot-starter-security
在代码中获得当前登录的用户
- 注入principle对象
- 或通过@AuthenticationPrincipal获取
- 通过安全上下文获取
密码转换器
- NoPasswordEncoder CSDN倾情奉献
- BCryptPasswordEncoder
- …
1 |
配置spring-security
使用filter-chain
1 |
|
使用webSecurityConfigAdapter
1 | public |
还可以对于业务层代码进行控制
1 | //执行前检查 |
背后的实现原理:就是面向切面编程,使用AOP技术
CSRF 跨站请求伪造
攻击者利用用户通过验证的session id或cookie对服务器进行攻击,譬如site B提供一个表单并让浏览器提交以攻击 site A,为了避免这种情况,site A提供一个csrf字段进行校验,如果一个表单无法提供_csrf字段,那么就认为不满足csrf
为用户定义角色
1 | // 在声明实现UserDetails的数据类中覆写 |
与视图连接
1 | <form method="POST" th:action="@{/login}" id="loginForm"> |
小寄巧:调整日志级别
application.properties里面
1 | loggin.level.org.springframework.security=debug |
解决csrf问题
记得在前端里面加上相应前端处理csrf的功能,比如thymeleaf就是th:action=”@{/add}”
1 | <form method="POST" th:action="@{/add}" th:object="${contact}"> |
用户认证
Security框架利用cookie验证用户,首次登录后服务端将提供set-cookie字段,这个字段将让浏览器在之后的请求时提供cookie,cookie中有session id,服务端用cookie和后端匹配后就可以保证登陆了
用户授权
在开发中使用spring security
- 实现一个接口:UserDetailService
- 提供PasswordEncoder
- 提供一个登录页面(如果不实现就会得到一个丑陋的页面)
- 调用HttpSecurity进行权限测试(可以通过继承webSecurityConfigurerAdapter,也可以通过bean FilterChain)
spring security帮我们做了什么?
- 实现用户登录控制器
- 请求重定向到用户登录页面
- 通过Filter对设定的权限进行控制
用户信息存储
- 内存用户存储
- JDBC用户存储
- LDAP用户存储(轻量级目录数据库)
HTTP Basic认证,提交请求的同时同步提供用户名密码,测试的时候很方便
可以让客户端在请求时带上一个Authorization请求头,带上加密的base64密码和用户名,这样服务端就不会重定向到登录页面了
启用basic
1 | .and() |
basic64不能用来加密,它很容易就会被破解,采用basic64为了将特殊字符转换成固定的64个字符,保证浏览器和后端可以兼容
如果想要获得当前用户信息
通过注入principle对象获取
1 |
|
想获得当前登录的用户对象
1 |
|
上下文获取
1 | SecurityContextHolder.getContext().getAuthentication(); |
配置属性
属性来源
途径一:application.yml application.properties
1 | server.port=8090 |
yaml
对象、键值对,使用冒号
1 | animal: pets |
途径二:命令行参数
1 | java -jar ... --server.port=8090 |
途径三:java虚拟机参数
1 | java -Dserver.port=8081 -jar ... |
途径四:操作系统环境变量
1 | set SERVER_PORT=8082 #windows |
环境变量不支持’.’,所以用’_’,这样比较适合不同环境不同配置
配置数据源
1 | spring: |
Keytool
- keytool是jdk自带的密钥库管理工具,位于%JAVA_HOME%\bin...
1 | keytool -genkey -alias lyl -keyalg RSA -storetype PKCS12 -storepass letmein -keystore mykeys.p12 |
数字签名
根据文档内容生成指纹,这个指纹在不考虑极小概率的碰撞下可以标识这个文档,可以用于防止篡改和验证身份
配置日志
1 | logging: |
自定义属性的使用
四个方案:
- 通过@ConfigurerationPorperties(prefix=’’)
- 通过@Value @Value(“${com.sam.desc}”)
- 通过环境变量
- 通过程序参数
1 | //记得注入props |
yaml中定义
1 | taco: |
1 |
|
在属性文件中定义相对复杂的数据结构
key-value结构
1 | discount: |
激活哪一个application.yml呢?
激活profile
假设有两个
application-ut.yml
application-st.yml
profile名分别是ut、st
- 环境变量激活:spring_profiles_active=st
- 命令行参数:java -jar … –spring.profile.active=st
- JVM系统属性:java -Dspring.profiles.active=prod -jar …
- 使用注解创建@Profile
1 | //不是st才生效,也可以对Bean生效 |
Actuator
暴露各种各样的端点(RESTapi url),要暴露多一些的话要include: “*”
提供获取当前程序信息的丰富的REASTapi
常用的一些端点
- /actuator
- /actuator/configprops
- /actuator/health
- /actuator/beans
分布式系统的配置数据来源
REST API开发
ReST原则 Representation State Transfer
- 资源 网络上的一个实体,一般用url标识
- 表现层 Json Xml Html
- 状态转移 服务端-客户端
- 四个常用方法Get Post Put Delete
@RestController(以及produces参数) @ResponeBody @RequestBody
状态码
- 1xx:继续发啊
- 2xx:成功
- 3xx:重定向
- 4xx:非法
- 5xx:服务端寄了
接口设计
- 使用合适的Http动词
- 使用url来传达意义
- 使用json作为请求和返回的格式
- 使用状态码来传达结果含义
前端开发基础
- HTML,CSS,JavaScript
- Node.js是一个Javascript运行环境,让javascript可以开发后端
- NPM 包管理工具
- 最著名的框架:Vue与React
- 前端开发常用架构MVVM
- 单文件组件:.vue 模版、逻辑、样式
REST
Representation State Transfer 表现层状态转移,资源从服务端到客户端是一种转移,从客户端到服务端也是一种转移
如果一个架构符合Rest原则,则成为RESTful架构
spring多模块开发
根模块应当依赖子模块,构建时,spring从根模块开始分析模块间的依赖,最终从最基础的模块向根模块自下向上构建
开发一个RestController
1 | //将通过ResponseBody将返回值作为json格式串返回给客户端 |
Http接口设计(必考)
看ppt
Spring Starter Rest
添加依赖
1 |
设置路径
1 | spring: |
还可以指定资源的名字
1 | @RestResource(rel="tacos", path="tacos") |
请求
http://tacacloud:8080/data-api/tacos?size=15&page=2&sort=createdAtdesc
客户端如何调用RestApi
使用restTemplate
1 | public Ingredient getIngredientById(String ingredient){ |
使用Feign调用REST API
1 | <dependency> |
1 |
|
@RequestMapping用于请求映射
响应头和响应体
- 状态行
- 状态码:1已接收 2成功 3重定向 4有非法 5服务寄
分布式环境下RESTapi的权限控制-OAuth2
OAuth2的过程
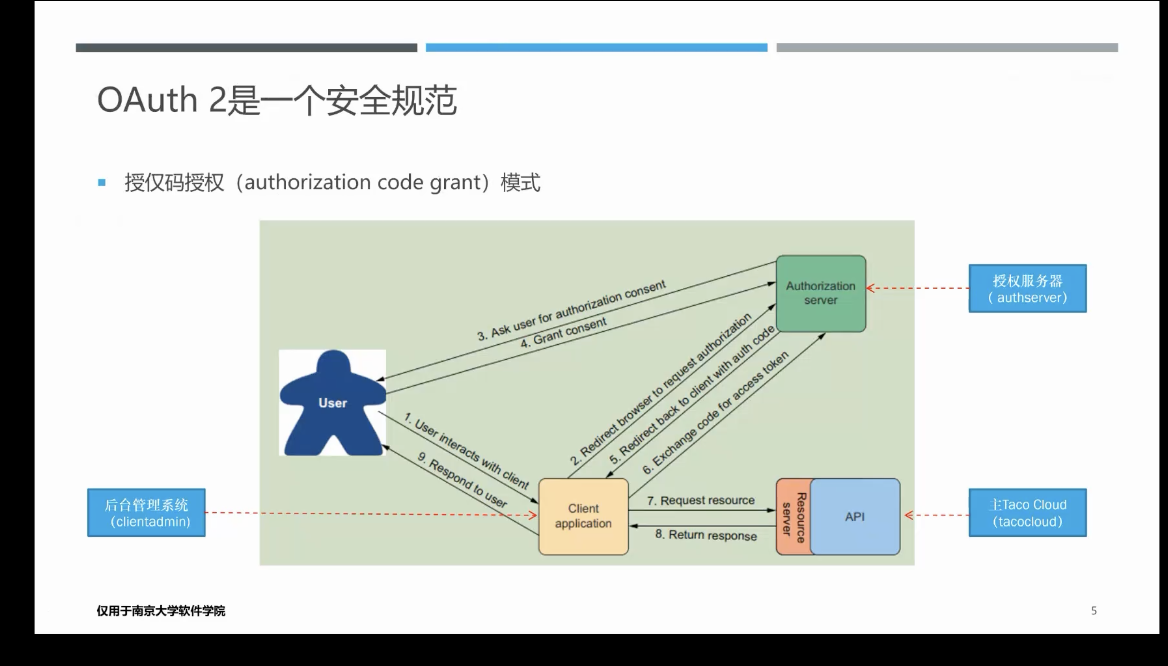
OAuth2的图很可能考
为什么客户端要先拿到code,再用code去请求token?
添加依赖
另外三种授权模式
- 隐式授权:授权服务器返回的不是Code,而是Token
- 用户凭证授权:直接用用户凭证向授权服务器索要令牌,而不是要用户登录
- 客户端授权:基于客户端特定的令牌授权
Auth服务器
auth服务器和客户端都会有相同的redirect url配置,auth服务器的url是用来校验的,如果不一样,auth服务器会认为客户端要求的redirect url是恶意地址
资源服务器
客户端
Security配置
1 |
在获得一个token后,客户端通过拦截器在每个请求上加上token
消息中间件 ActiveMQ、RabbitMQ
同步与异步
消息中间件
消息代理,作为消息接收的第三方,在生产者和消费者之间,这样两边都不必关心对方了
实现生产者和消费者的解耦
常见的消息中间件
- ActiveMQ
- RabbitMQ
- kafka
Postman => Taco Cloud => 消息中间件 => Kitchen
JMS
java消息服务,定义了java使用消息代理的通用API
spring有支持JMS的模版JmsTemplate
重要概念
- connectionfactory:到消息服务器的连接池
- connection
- session
- destination
- message
消息的序列化和反序列化:消息转换器
jackson2转为json最常用
两种接受消息的模式:拉取和推送
Pull模式:消费者主动向消息中间件拉取消息 (TacoOrder) JmsTemplate.receiveAndConvert("tacocloud.order.queue");
Push消息中间件主动将消息推送给消费者
@JmsListener(destination = "tacocloud.order.queue") public void receiveOrder(TacoOrder order) { ui.displayOrder(order); }
RabbitMQ
创建交换机和队列
重要概念
- ConnectionFactory Connection Channel
- Exchange
- Queue
- Routing Key
- Binding Key
ActiveMQ Artemis
支持协议
- JMS
- AMQP 也是RabbitMQ支持的协议
- MQTT(物联网常用)
支持Native内存模式 与 JVM模式
分布式架构,消息持久化
生产端
1 | public static void main(String[] args){ |
消费端
1 | public static void main(String[] args){ |
Taco Cloud应用添加发消息功能
生产侧
1 | public interface |
获取第三方jar包源码:mvn dependency:sources
想把代码文档翻译的话就用Translation 插件
1 |
|
converter
1 |
|
消费侧
取消息有两种方式:主动去哪或者artemis推送给你
1 |
|
RabbitMQ
ConnectionFactory Connection Channel
Exchange: Default Direct Topic Fanout Headers DeadLetter
- Exchange根据Routing Key和Binding Key将消息分发到不同的Queue
- Direct exchange根据key发送
- Fanout exchange直接将消息广播给所有连接到它的Queue
Queue
Routing Key
- Sender给消息指定Routing key
Binding Key
- 每个Queue有Binding key
- Binding key是可以用通配符的
依赖
1 | <artifactid>spring-boot-starter-amqp</artifactid> |
发送
1 | public void sendOrder(TacaOrder order){ |
消费方只需要关心队列的名字,什么key,exchange都是发送方才关心的事
AMQP是一个消息协议
Spring Integration
集成流 integration flow
集成流组件要重点了解
网关
集成流配置
- XML配置
转换器
进来的内容可以和出来的内容不一样
路由器
Adapter
切分器
一个消息分成多个消息
服务激活器
消息进来后调用一个服务进行处理
使用MessageHandler会将消息消费掉
使用GenericHandler处理完消息后还会把消息丢到目标channel去
转换器和服务激活器的区别?处理过程上二者没有区别,但是从业务上说,Transformer是为了对消息进行转换,服务激活器则是为了激活另一个服务(比如做一次存储,掉一个外部服务等等)
网关
除了单向还有双向网关
1 |
通道适配器
反应式编程
反应式编程解决的问题
反应式编程面向IO密集型场景,
IO非常明显的一个特点就是会出现等待,当IO密集时,往往线程也很多,线程之间的切换需要比较大的开销,如果CPU要管理大量的线程,自然速度就会很慢,因为大量的时间都被用于线程的切换
为了解决这种问题,我们引入事件轮询机制,将原来的为每一个客户端提供服务的线程释放,现在客户端都统一通过发送request请求来加入一个事件队列,一个线程轮询事件队列来不断地处理
反应式编程是消费方驱动的,没有收到request,publisher是不会没事找事的
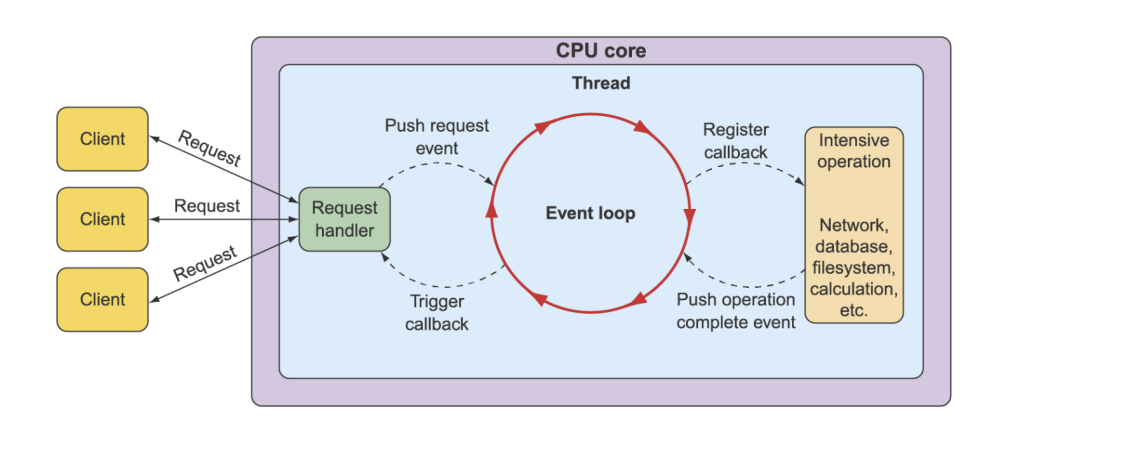
两种编程模式
- 命令式
- 反应式
Reactor
和java默认stream的区别
默认的是同步的,其实只是一种用函数来迭代处理集合的方式
webflux
启用基于响应式编程的web应用程序的开发,提供类似Spring MVC的编程模型
反应式流规范规定的四个接口
这里非常重要
- publisher:发布消息
- processor:加工传递消息
- subscriber:订阅消息
- subscription:协调publisher和subscriber
Subscriber
注意b.subscribe(a)是a订阅b
1 |
|
Publisher
Subscription
回压
四类操作:创建、组合、
reactor反应式流图
Flux:包含0到N个元素的异步序列
Mono:包含0或者1个元素的异步序列正常的包含元素的
消息:序列结束的消息嗯序列出错的消息
操作符:对流上元素的操作
Flux的合并
- merge
- zip(默认合并成元组,也可以合并成指定类型)
- first 只取首先产生消息的流
flatMap可以将一个流又转换成一个新的流,比如从一个Flux转为一个Mono(这样做可以让Mono跑在不同的线程里,形成多线程),可以用.subscribeOn(Schedulers.parallel())让流并行的跑
flatmap可以扁平化流
schedulers还有
- immediate
- single
- parallel
map和flatmap的区别:(很重要)
Spring WebFlux
启用基于响应式编程的Web应用程序的开发,提供类似于Spring MVC的编程模型
目前讲的三类消息:
- 反应式编程和Integration中的消息:在java虚拟机内,所以不用序列化
- RabbitMQ等消息中间件的消息要在外部传输,需要序列化
Spring MVC和Spring WebFlux共性与不同
- MVC底层是Servlet,基于Servlet API
- WebFlux底层是Netty,基于Reactive HTTP
- WebFlux通过Router Function实现请求处理
block和blocklast会阻塞调用它们的线程直到拿到结果,用subscribe的话结果可能就拿不到了
Repository
reactive.ReactiveCrudRepositoy
基于函数式编程的请求处理
- 使用函数式编程风格定义endpoints
- 两个基本组件HandlerFunction RouterFunction
webclient: 对应resTemplate
1 |
|
反应式编程测试webTestClient
1 | webTestClient.get().uri(...).accept(MediaType.APPLICATION_JSON).exchange().expectStatus().isOk().expectHeader().contentType(MediaType.APPLICATION_JSON).expectBody(Greeting.Class) |
docker常用命令
docker镜像构建与服务编排
Dockerfile
1 | docker build -t mysite:latest . |
其中.是构建上下文
编写dockerfile之最佳实践
.dockerignore: 拷贝文件时不要拷贝这些文件
容器只运行单个应用
多个run指令合并为一个,不然你会整出一堆层来
基础镜像标签不要用latest,不然可能出现兼容问题
每个run指令执行后立刻删除多余文件,不然即使下一层删除也仅仅只是本层不可见而已
采用精简版本的镜像,比如Buster、Alpine
设置WORKDIR和CMD,不然它会重用基础镜像的CMD,还可以采用EntryPoint结合CMD来灵活的决定运行哪一个分支
合理的调整指令的顺序,改动少的要放到前面,这样可以充分利用缓存
添加HEALTHCHECK,比使用–restart always更厉害,可以让docker daemon在一些条件下重启容器
1 | HEALTHCHECK CMD curl --fail http://localhost:$APP_PORT || exit 1 |
Docker Compose
docker-compose.yml 希望指定部署哪些服务
使用缩进表示层级关系