软件测试
- 源代码
- 移动应用
- 智能软件
方向survey 20%
另一个方向实现工具 30%
期末考试 40%
课堂报告 5%
课堂小测试 5%
课后小测试 5%
自动化是软件测试的一个梦想
什么是bug
Fault:静态的,就是写错了
Error:跑的时候出错了,或者跑的时候产生的不正确状态
Failure:跑出来的结果是错的
测试用例
execution:运行到出错的代码
infection:触发出错误
propagation:错误传播到输出
bug有空间聚集的趋势
测试的局限性
- 输入空间庞大
- 实现逻辑复杂
- 测试预言未知
随机测试
- 测试执行次数够多
- 测试数据随机生成
- 概率低的偶然现象发生
常见bug
- 断言失败
- 异常崩溃
- 无效输入
- 错误输出
模糊测试
本质上就是带反馈的随机测试,基于bug的聚集性
经典测试技术
- 变异测试
- 把程序改错,然后拿测试用例来试,如果程序出错了,那么说明测试用例是有错误检测能力的,如果用例仍然被通过了,这意味着测试用例是很弱的
- 执行代价非常高,如何高效执行编译测试是企业面临的一大问题
- 蜕变测试
- 多次执行目标程序时,输入输出之间期望遵循的关系,比如sin函数应该呈现出2π周期性
- 差分测试
- 将同一测试用例1运行到一系列相似功能的应用中观察执行差异来检测bug
自动化测试
自动化测试脚本修复
程序修复
mindmap
id(自动化测试)
自动化测试脚本修复
程序修复
测试用例推荐
基于互联网群体
智能的软件测试
自动化测试发展路线
stateDiagram
确定步骤的自动化 --> 非确定步骤的自动化
非确定步骤的自动化 --> 具有学习能力的自动化
发展热点之智能软件测试
有时候删除神经网络的一部分反而会提高了系统的准确度
常用测试方式
边界值测试
训练数据的偏见会带来模型的偏见
变异测试
变异测试背景
正向使用:修复程序的错误,产生新的测试用例
反向使用:产生错误的程序片段(变异测试的主要部分),生成恶意测试用例
方向控制:引导&反馈
关心的问题
- 如何编写能够暴露缺陷的测试用例
如何引导测试 - 如何评估测试套件的质量
如何评估测试
变异测试的产生
- 模拟缺陷,量化缺陷检测能力,扮演测试有效性的指示器
- 模拟:变异产生错误版本
- 量化
研究现状
广泛关注(赢赢赢)
变异分析
黑话:
自动化生成人工缺陷:自动化变异源程序进行分析
变异体:语义变体,语法上语义上与源程序都不相同
变异算子:变异:程序变换规则
变异得分:变异测试对测试套件错误能力检测的量化
变异体的杀死与存活
缺陷传播模型:PIE(Execution,Infection,Propagation),RIPR(Reachability,Infection,Propagation,Revealability)
杀死条件:
- weak
- firm
- strong
变异体的分类
- 有效变异体
- 无效变异体
- 夭折变异体
- 等价变异体:和源程序语义相同
- 重复变异体:两个变异体语义相同
- 蕴含变异体:所有能杀死A的,都能杀死B
变异算子:
一系列语法变换规则
变异的依据
基本形式:
- 源代码变换
- 字节码变换
- 元变异
变异测试为什么有效?
- 假设1:缺陷是简单的,可模拟的
- 假设2:缺陷可叠加
- 假设3:缺陷检测有效性
变异测试过程
stateDiagram
变异体筛选、创建 --> 去除重复和等价的变异体
去除重复和等价的变异体 --> 生成测试输入
生成测试输入 --> 执行变异体
执行变异体 --> 计算变异得分
计算变异得分 --> 优化、排序
优化、排序 --> 覆盖阈值是否达到
覆盖阈值是否达到 --> 测试套件是正确的吗: yes
覆盖阈值是否达到 --> 生成测试输入: no
测试套件是正确的吗 --> 结束: yes
测试套件是正确的吗 --> fix测试套件: no
fix测试套件 --> 变异体筛选、创建
变异体筛选、约简
变异算子定义
设计原则:变异算子定义
如何有效设计变异算子:
- 根据编程语言
- 根据语言设计原则
- 根据应用场景
- 根据bug类型
约减策略:
- 随机选取
- 基于类型
- 基于分部
变异体生成
- 将选中的变异体实例化
- 基本方式:每个变体构建一个单独的源文件
- 核心:程序模式
- 研究方向:怎么把算子生成过程的开销减少
- 元变异,基于中间表示的变异体生成,热替换(直接在运行时生成变异体)
元变异
- 核心:程序模式
- 目的:减少生成变异体时所需的编译次数
基于中间表示
- 避免编译
- 直接操作中间目标:比如操作java字节码,.NET和LLVM中间表示
变异体优化
基本形式:通过静态分析的形式,识别并移除有问题的变异体
识别等价变异体,识别冗余变异体
变异体的执行
变异测试中最昂贵的部分
研究内容:
- 计算变异得分:研究集中在变异杀死的条件(对于确定性系统,对于非确定性系统)、测试预言的条件(预言怎样搞出更好的的测试套件)
- 计算变异体矩阵:注意如果测试套件中有一个测试用例把变异体杀了,就不用再往下走了,由此可以有一些优化策略比如:改变测试顺序、匹配测试用例与变异体、避免执行必定存活的变异体、限定变异体的执行时间
变异测试的应用
- 评估作用
- 引导作用:利用变异测试
- 传统应用:应用于确定性系统
- 测试生成
- 预言生成
- 测试优化
- Debug引导
- 变异&AI:应用于非确定性系统
用例与预言生成
- 基于搜索的软件测试+变异分析
- SBST,将软件测试过程转化为搜索问题,利用启发式算法
- 变异引导的单元测试及预言生成
变异辅助debug
利用变异自动为有缺陷程序推荐补丁
- 缺陷定位技术:
- 抽象测试轨迹,计算可疑度
- 自动修复技术
- 根据一定的语法规则转换缺陷程序为正确版本
- 缺陷定位技术:
挑战:
AI测试TCP
通过变异分析进行DNN测试输入排序
- 变异分析+测试排序+AI测试
- TCP for DNN:谁应当最先被打标签
- MA for DNN:模型的变异、输入的变异
- 核心思路:越能杀的测试优先级越高
模糊测试
模糊测试架构
- 工具:模糊器
- 目标:待测程序
- 循环:执行程序
崩溃分派 - 三个组件
stateDiagram
direction LR
Fuzzer --> ExecuteProgram: Test inputs
ExecuteProgram --> PUT
PUT --> CrashTraige: Execution result
CrashTraige --> Fuzzer
CrashTraige --> Crashes
黑话
- 模糊是指从输入空间采样得到的输入来执行待测工具的过程,代表着测试人员针对待测程序定义的预期输入
- 模糊测试是一种应用模糊过程来检测
- 模糊器:一组用于实现
- 缺陷语言:确定一次给定执行是否违反正确性策略的程序
模糊测试家族
- AFL(C/C++)
- LibFuzzer(C/C++):一个基于LLVM的工具
- JQF(Java):AFL搬到了java上
- 其他(Rust(强化版c),Python等)
模糊测试分类
根据组件核心或技术贡献进行分类
- 按照采用的运行时信息:黑盒(很多嵌入式系统的设置)、灰盒(看一部分信息,比如覆盖率)、白盒(强力的程序分析手段融入到程序中)
- 按照输入生成的策略:基于变异的,基于文法的
- 按照引导过程:启发式算法、梯度下降
- 按照测试目标:定向、非定向、某一类缺陷
- 按照应用领域:网络协议、Compiler、DNN、IoT、内核
- 按照优化角度:种子调度、变异策略、能量调度、过程建模
黑盒模糊测试
常用于IoT
引导方式:利用输入格式或输出状态引导测试执行
优点:不用插桩效率高,但是引导不好
白盒模糊测试
使用混合执行、污点分析等比较昂贵的分析技术
引导方式:利用详细的程序分析结果引导测试执行
优点:反馈更加有效,但是效率不高、适配性差
灰盒模糊测试
最流行
轻量级插桩进行监控
利用得到的部分信息引导测试
代表工作:AFL、AFLGo、EcoFuzz、Zest、BeDivFuzz
基于变异的模糊测试
本质:将种子输入转换成bit串,对比特串进行变换
优点:可拓展性强,易于泛化
缺点:容易破坏输入的结构、产生无效输入;生成的大部分输入都无法通过语法检查
AFL变异算子
- bitflip 翻转
- arith 加减小整数
- interest 翻转有趣的字节位
- havoc 总结上面的
- spilce 随机拼接两个种子输入
SLF
思想:分析程序中的语义检查、识别比特串中与影响语义检查的域、根据两者之间的关系制定变异策略
基于生成的模糊测试
基于一定的文法规则/结构信息
- 利用给定的、或者挖掘/学习得到的文法规则,来构建能够通过(语法)检查的结构化输入
- 优点:容易生成合法、有效输入,适用于对输入结构性要求较高的场景如编译器测试
- 缺点:需要人工赋予一定的领域知识
Inputs from Hell
挖掘已有的测试输入,得到现有的测试输入分布,根据该分布进行输入生成以得到预期的测试输入
可以生成相似输入或者相反输入
按引导方式分类
基于搜索
将测试转化为搜索问题,以代码覆盖率为指示器、以启发式算法(类遗传算法)为核心,将测试导向更高覆盖的方向
如CGF
基于梯度
将测试转化为优化问题,以最大化缺陷
示例:设计一个模糊测试
- 定义输入:一个操作序列,有一系列原子操作组成
- 定义输出:可以是插桩得到的值,也可以是程序本身的输出
- 种子调度:种子优先级排序,更长的序列优先,得分更高的序列优先,基于feedback结果计算energy
- 测试生成
- 执行
- 结果反馈
软件工程综述
RWPH:SE研究的四个维度
- Reading
- Writing
- Presenting
- Hacking
以新颖的的方式总结和组织最近的研究成果、整合并添加对该领域工作的理解和认识的研究工作
- 总结有关技术的现有进展
- 总结当前某个领域研究的不足
- 提供研究框架/背景
- 检查经验证据在多大程度上支持/反对理论假设,甚至提出新的假设
综述研究流程
- 三个环节,五个步骤
- 规划、实施、报告
- 五个步骤
- 框架搭建
- 文献检索(这次作业要50篇,最不济20~30篇)
- 文献阅读(主要读摘要)
- 文献分类(分成3~6个正交类别)
- 文献分析
- 写作的逻辑性
- 善用总分结构
- 注重语句之间的连贯性
测试用例优先级
软件演化:如何确保演化后软件产品的质量?
回归测试
前一个版本的用例放到新版本跑,看看旧的功能有没有受到影响
回归测试一般占测试预算80%以上,占产品维护50%以上
重新执行已有测试用例
- 用例庞大跑不完
- 用例冗余浪费算力
- 用例失效,接口改了,功能砍了,逻辑变了
- 用例缺失,新的测试需求没有被覆盖
回归测试优化
测试用例优先级
依照某种策略赋予每个测试用例不同优先级,以提高测试用例集的故障检测率
采用启发式算法操纵测试用例,是的优先级较高的算法能够优于低优先级的算法执行
测试用例约减
通过识别并移除冗余测试用例来降低成本
通过覆盖来进行评价
优先级策略
基于贪心的TCP策略
- 全局贪心
- 每轮挑选覆盖最多的测试用例
- 多个用例相同随机选择
- 增量贪心
- 每轮优先挑选覆盖最多,且未被一选择用例覆盖代码单元的测试用例
- 所有代码单元都被覆盖则重置优先级排序
- 多个用例相同随机选择
- 全局贪心
基于相似性的TCP
基本思想:如果一堆测试用例显示的异常聚在一起,那它们测到的很可能是同一个bug,所以相似的测试用例往往测到相同的bug,所以我们选择测试用例时应当选得均匀一些
基于搜索的TCP


基于机器学习的TCP
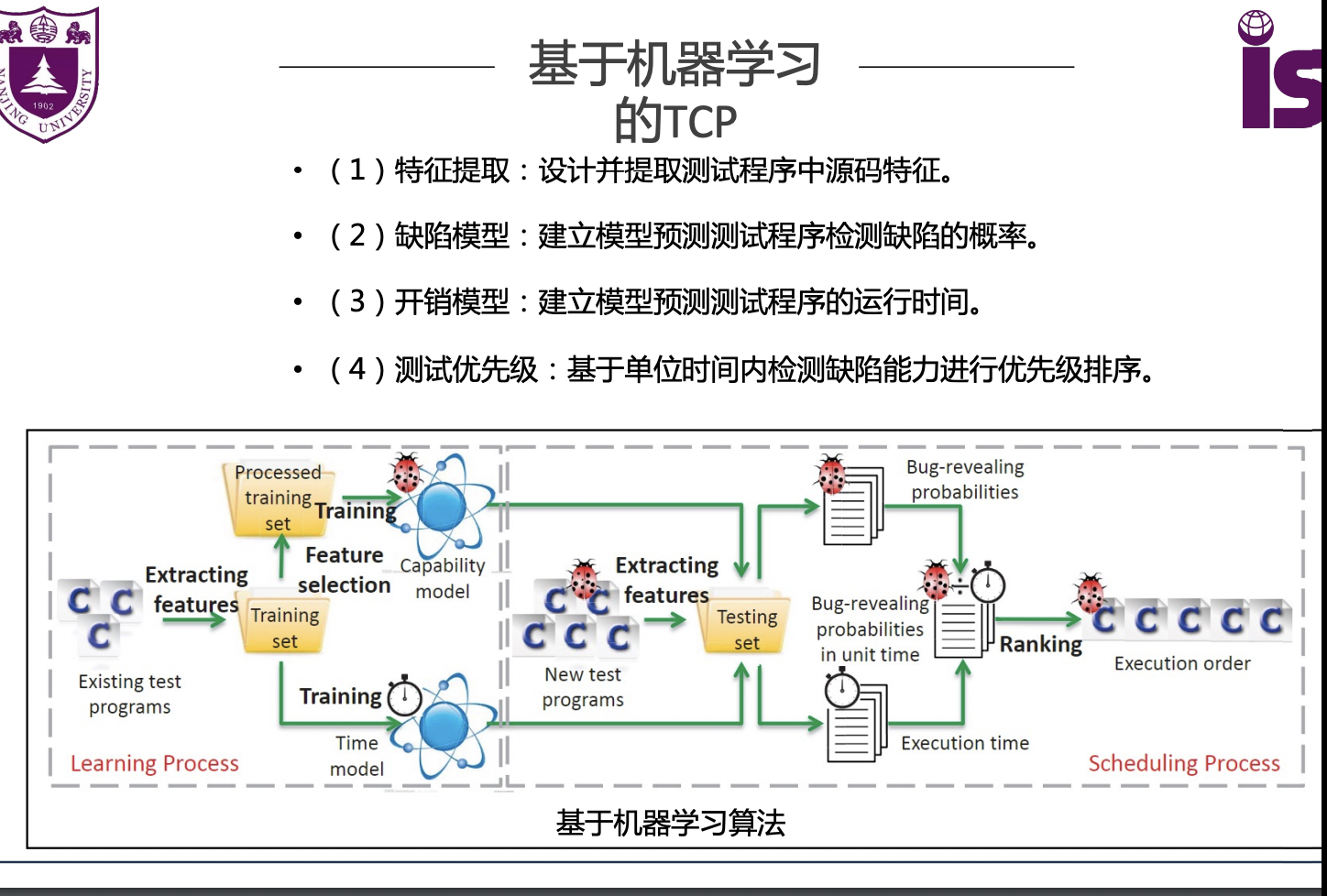
评估指标
APFD 平均故障检测百分比
给定包含m个故障
T‘为T的一个优先级序列,TFi为地i个故障第一次被检测到时的下标,那么APFD为
缺点:未考虑测试用例的执行开销(有的用例一跑跑几天)和缺陷危害程度(有的只是渲染问题,有的导致用户密码泄露,有的导致服务器被注入)

NAPFD归一化平均故障检测百分比
特点:考虑实际优先级排序场景中
- 测试用例集不能检测所有缺陷
- 由于资源限制无法检测所有的测试用例
基于学习程序修复技术
移动应用众包测试
众包:利用群体力量来完成传统方法中成本高昂或更耗时的大规模任务
举例:很多验证码其实是一半真的有答案,一半则是在利用用户的识别能力来获取数据集
移动应用碎片化问题:品牌、型号、系统、传感器…
uTest、Testin、Baidu Crowd Test,Alibaba Crowd Test,TestIO,MoocTest
- 申请上传
- 任务选择和环境设置
- 提交报告
- 生成最终测试报告
- 报告验证
众包测试中的缺陷类型
- 功能缺陷
- 显示问题
- 性能问题
- 布局问题
- 应用崩溃
- 错误提示
- 空白屏
众包测试面临的挑战
- 任务分配
- 任务奖励
- 众测过程引导
- 测试报告质量控制
协作式众包测试
- 完成测试任务过程中进行信息共享与任务分配,用户在本系统中既承担测试任务也承担审核任务,充分利用用户协作,完成目标任务
- 信息共享:用户在提交报告时进行实时相似报告推荐,避免重复报告提交
- 任务分配:审核页面推荐待审核的报告列表,测试页面推荐待测页面
- 协作方式:点赞点踩
- 一键fork
功能测试
- 根据需求来细分功能点
- 根据功能点派生测试需求
- 根据测试需求设计功能测试用例
- 逐项执行功能测试用例验证
测试类型
- 正确性测试
- 可靠性测试
- 易用性测试
性能测试度量方法
- 服务器采用cpu、内存使用率
- 客户端根据系统处理用户请求的时间
负载测试
- 负载测试用于验证应用系统在正常负载条件下的行为
- 性能行为通过一些性能指标体现
- 两种方式
- 直接到达负载数
- 逐步增加复杂数(可以测到系统负载的上限)
压力测试
评估系统处于超过预期负载的行为
不一定是关注性能行为,可能是某种bug,比如同步、内存泄漏
系统不应该崩掉
可以测到系统崩溃的临界点
历史区测试法
- 恶邻测试法:经常出bug的地方的旁边也经常出bug
- 博物馆测试法:很久没用的代码很容易失效
娱乐区测试法
- 配角测试法:重要功能旁边的功能重点关注
- 深巷测试法:测试那些最不可能被用到的特性
- 通宵测试法:一直让程序运行,看他能坚持多久
众测报告聚合
Aggregator
- 截屏集合的距离矩阵DS计算
- 文本集合的距离矩阵DT计算
具体实现:合成层次聚类,Summarizer
众测报告排序:
- 文本
- 关键词提取
- 计算文本距离
- 图片
- SPM算法计算图像距离
- 计算图片距离时要设法屏蔽掉一些无意义的内容,比如不同的主题背景造成的截图不同
将每份报告的文本距离和图片距离组合起来
于是就可以将这些报告分成一个一个有层次的聚类
测试预言问题
测试预言是自动化软件测试中不可或缺的一部分
测试预言可以是:
- 体现被测单元预期功能的文档
- 是验证程序功能的机制
- 判定程序执行是否正确的程序
- 约束
- 映射(比如执行结果映射到成功或失败)
显示预言:通过assert之类进行显示检测
隐式预言:通过程序崩溃等很明显的错误进行检测
预言问题
给定系统输入,如何找到能够正确鉴别出符合期望的正确行为与发现潜在的不正确行为测试预言的挑战性难题
蜕变测试
测试用例生成新思路
虽然不能通过成功测试用例排除程序存在缺陷的可能,但是可以用相关的测试用例指导之后的测试
蜕变测试的几大注意点:
不是所有的必要属性都能作为蜕变关系
蜕变关系应当和多个输入实例相关
不是所有的蜕变关系都能够划分成输入端和输出端
蜕变关系不要求一定是等式关系
有测试预言也可以做蜕变测试
差分测试
找一些竞品来,看看对于相同的输入,输出结果或者行为有没有区别,如果有就说明至少有一个竞品有问题
移动应用自动化GUI测试
自动化测试框架
selenuim web页面测试
appium 扩展了selenium,可以用selenium库来编写应用测试脚本
appium
- 基于webdriver协议
- 客户端库
- 会话控制
- 命令执行
- 元素定位与交互
- 无需修改应用
- 跨平台
- 无需修改应用
- 模拟器和真实设备
测试往往是通过人工录制+自动化回放,也有基于模型的自动化测试技术
存在的问题
- 测试脚本的执行依赖于操作系统接口
- 定位空间依赖GUI
- 人工编写脚本开销大
- 脚本随应用迭代的维护困难
基于图像的空间定位
通过图像匹配算法来完成对GUI元素的识别和定位
- 捕获屏幕图像
- 编写脚本
- 图像识别
- 相似度阈值
- 执行操作
- 反馈和调整
深度图像提取UIED
布局理解、控件意图识别
基于深度图像理解的录制回放工具
- 无法感知异形屏幕对UI控件的遮挡
- 难以模拟真实场景下人的交互操作
- 仍依赖操作系统接口执行测试操作
解决:从侵入式转为非侵入式
机械臂+AI
期末
源码测试
- 随机测试
- 变异测试
- 查分测试
- 蜕变测试
应用题
- 测试用例优先级
- 主要算法的流程及复杂度
- APFD计算
- 算法应用
- 测试用例选择
- 主要方法
- 动态静态
- 与测试用例优先级的区别和联系
- 测试用例优先级&
随机测试
大数定律
测试执行次数够多、测试数据随机生成
概率低的偶然现象发生
变异测试
变异测试旨在找到有效的测试用例,发现程序中真正的错误,用于检测测试用例是否足够强悍
这里说的变异和AI测试中常用的数据增广的变异方法是相似的,但是测试的对象不同
蜕变测试
通过输入与输出之间期望遵循的关系来判断测试是否通过,譬如sin函数的测试用例,180度互补的结果应当是一致的
差分测试
通过将同一测试用例运行到一系列相似功能的应用中观察执行差异来检测bug
移动应用测试
- 基于图像理解的移动应用自动化测试
- 能够了解各个任务的难点
- 能够论述各个任务的解决方法
- 核心思想
- 方法步骤
- 基于群智协同的众包测试
- 能够了解众包的难点
- 能够了解基本的机制
- 能够了解解决办法
AI测试
- AI测试概述
- 与传统测试的区别
- 测试的难点
- 模糊测试
- 基本流程
- 数据生成
- 结果反馈
- 简单应用
- 图像测试
- 公平性
- 后门攻击