准备
Android 八股
初级
什么是ANR,如何避免ANR
ANR是Application NotResponding,ANR出现可能的原因包括:
- 主线程被IO操作阻塞
- 主线程中存在耗时操作
- 主线程存在错误操作,比如Thread.sleep()
- 应用5s内为响应用户的输入事件(按键或触摸)
- BroadcastReceiver未在10秒内完成相关的处理
- Service在特定的时间内无法处理完成 20秒
解决方式
- 不要把IO塞进主线程,使用AsyncTask
- 主线程中的耗时操作如访问网络、Socket通信、大量SQL查询、复杂计算放入子线程中
- 正确设置线程的优先级
- 使用Handler处理线程工作结果,而不是使用wait和sleep
- Activity的onCreate和onResume回调中尽量避免耗时的代码。 BroadcastReceiver中onReceive代码也要尽量减少耗时,建议使用IntentService处理。
Activity和Fragment的生命周期
stateDiagram Activity_onCreate() --> Fragment_onAttach() Fragment_onAttach() --> Fragment_onCreateView() Fragment_onCreateView() --> Fragment_onActivityCreate() Activity_onStart() --> Fragment_onStart() Activity_onResume() --> Fragment_onResume() Fragment_onPause() --> Activity_onPause() Fragment_onDestroyView() --> Fragment_onDestroy() Fragment_onDestroy() --> Fragment_onDetach() Fragment_onDetach() --> Activity_onDestroy()手机切换横竖屏时生命周期的变化
如果没有设置configChanges,那么切屏会把各个生命周期全走一次(从onPause()开始到新Activity的onResume())
为什么Android APP出现延迟?
- APP 经常运行GC,而GC运行时APP无法运行android UI 往往16ms刷新一次,如果GC占用了时间,APP 只能跳过一些UI 帧,看起来就像UI出现了卡顿
- 主线程中运行耗时的任务
解决
- 在需要时再实例化对象,不要提前实例化对象,使用懒加载
- 减少使用封装类如Integer
- 使用ArrayMap和SparseArray
- 使用对象池避免内存
- 将主线程中的耗时任务移到子线程中
什么是Context?
Context提供了关于应用环境全局信息的接口。它允许获取以应用为特征的资源和类型,是一个统领一些资源(应用程序环境变量等)的上下文。就是说,它描述一个应用程序环境的信息(即上下文);
主要的Context有两种:
Application Context 一般建议使用Application Context,不要让生命周期比Activity长的组件持有Activity Context
Activity Context
AOP技术方案
AspectJ-我们在Spring课程上学到的方法
@Aspect
@EnableApsectJProxy
@PointCut(“exectution(* …方法)”)
@Before/After/AfterReturned/AfterThrow/Around
真正意义的AOP,无需硬编码切面,可能存在重复织入、不织入的问题
APT
通过注解减少模板代码,对原工程具有侵入性
ASM
面向字节码编程的切面,一些场景需要硬编码
Javassit
有动态切片能力,上手快
动态代理
运行时扩展代理接口功能
APK打包过程
- 编译器将您的源代码转换成 DEX(Dalvik Executable) 文件(其中包括运行在 Android 设备上的字节码),将所有其他内容转换成已编译资源。
- APK 打包器将 DEX 文件和已编译资源合并成单个 APK。不过,必须先签署 APK,才能将应用安装并部署到 Android 设备上。
- APK 打包器使用调试或发布密钥库签署您的 APK:
- 如果您构建的是调试版本的应用(即专用于测试和分析的应用),打包器会使用调试密钥库签署您的应用。Android Studio 自动使用调试密钥库配置新项目。
- 如果您构建的是打算向外发布的发布版本应用,打包器会使用发布密钥库签署您的应用。要创建发布密钥库,请阅读在 Android Studio 中签署您的应用
- 在生成最终 APK 之前,打包器会使用 zipalign 工具对应用进行优化,减少其在设备上运行时的内存占用。
AsyncTask
轻量级的异步任务类,在线程池中执行后台任务,将执行进度和结果传递给主线程
生命周期
即使创建它的Actvity销毁,AsyncTask也会继续执行知道doInBackground执行完毕,如果没有调用cancel方法,他会调用onPostExecute,这时程序很可能会崩溃,因为它想回传结果的Actvity已经不存在了
同时由于AsyncTask作为一个非静态内部类持有了Activity的引用,如果AsyncTask还在执行,Activity就无法被释放,引起内存泄漏
结果丢失
如果Activity自己挂了,比如没有设置onChange的屏幕旋转,会导致AsyncTask将结果传给一个死掉的Activity从而丢失结果
并行与串行
随版本不同,最早直接并行,但是容易爆掉,后改成线程池,还是有问题,于是默认串行,可以用executeOnExecutor()来并行执行
AsyncTask原理
- AsyncTask中有两个线程池(SerialExecutor和THREAD_POOL_EXECUTOR)和一个Handler(InternalHandler),其中线程池SerialExecutor用于任务的排队,而线程池THREAD_POOL_EXECUTOR用于真正地执行任务,InternalHandler用于将执行环境从线程池切换到主线程。
- sHandler是一个静态的Handler对象,为了能够将执行环境切换到主线程,这就要求sHandler这个对象必须在主线程创建。由于静态成员会在加载类的时候进行初始化,因此这就变相要求AsyncTask的类必须在主线程中加载,否则同一个进程中的AsyncTask都将无法正常工作。
onSaveInstanceState()与onRestoreInstanceState()
首先他们都不属于生命周期方法,当应用遇到意外情况(内存不足、用户按Home时被调用)系统销毁Activity时调用,用户主动销毁时(如按返回键)不会调用
onSaveInstanceState适合保存临时性的状态,而持久性的状态应当放在onPause中保存
Android中进程的优先级
- 前台进程:正在与用户交互的Activity或是相应的Service,在内存不足时最晚被杀死
- 可见进程:处于onPause状态的Activity或者绑定在其上的Service,用户可以见,但是失去焦点用户不能交互
- 服务进程:使用startService方法启动的Service,用户不可见但是用户关心,比如浏览器下载进程,音乐播放器播放的音乐
- 后台进程:onStop的程序,比如后台的QQ
- 空进程:系统不会允许你的存在
Bundle传递的对象为什么要序列化?Serializable和Parcelable的区别?
Bundle传递数据时只支持基本数据类型,所以传递对象时需要序列化转换为可存储可传输的字节流,序列化后的对象可以在网络、IPC之间进行传输,也可以存到本地
- Serializable java提供
- Parcelabel Android提供:将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型
动画
View动画:作用对象是View,可用xml定义,建议xml实现,支持平移缩放旋转透明度四种变化
帧动画:通过AnimationDrawable实现,容易OOM
属性动画:
- 可作用于任何对象、可用xml定义
- 包括ObjectAnimator、ValueAnimator、AnimatorSet
- 时间插值器:根据时间的流逝决定属性的改变,预制匀速、加速、减速等插值器
- 类型估值器:根据当前属改变的百分比计算改变后的属性值,系统预置整型、浮点、色值等类型估值器
- 尽量避免使用帧动画,界面销毁时停止动画,开启硬件加速(将CPU的一部分工作分摊给GPU,使用GPU完成绘制工作)
补间动画:通过指定View的初末状态和变化方式,对View的内筒完成一系列的图形变换来实现动画效果。Alpha、Scale、Translate、Rotate,补间动画并没有真正改变View的位置,触摸区域并没有真的变化
属性动画原理
- 计算属性值
- 计算已完成动画分数:根据选用的Animator得到计算一个0-1的分数
- 计算插值(动画变化率):当Animator计算得到动画分数后,它会调用当前设置的TimeInterpolator,去计算得到一个interpolated分数,在计算过程中,已完成动画百分比会被加入到新的插值计算中
- 计算属性值:当插值分数计算完成后,Animator会根据插值分数调用合适的TypeEvaluator去计算运动中的属性值
- 为目标对象的属性设置属性值,应用和刷新动画
插值器:根据时间流逝百分比来计算属性变化百分比
估值器:根据插值器的结果计算出属性到底变化了多少数值
属性动画如果设置为无限循环,必须在界面销毁时停止动画,否则引发内存泄漏
- 计算属性值
Context
- Activity和Service的Context和Application的Context是不一样的,Activity继承自ContextThemeWraper,其他的继承自ContextWrapper
- 每一个Context都是一个新的ContextImpl对象
- getApplication只能在Activity和Service中用,如果要在别的地方用那么调用getApplicationContext()
- 创建对话框时不可以用ApplicationContext,应当用ActivityContext
- Context的数量等于Activity的个数+Service个数+1(Application)
- 不要给生命周期长于Activity的对象传Activity的Context,否则Activity无法被GC回收引发内存泄漏
Android各版本特性
Android处理Json
使用GSON包进行解析
解析成实体类
1
2Gson gson = new Gson();
Student student = gson.fromJson(json1, Student.class);解析成数组
1
2Gson gson = new Gson();
int[] ages = gson.fromJson(json2, int[].class);解析成List
1
2Gson gson = new Gson();
List<Student> students = gson.fromJson(json3, newTypeToke<List<Student>>(){}.getType);Android解析Xml
DOM解析
优点:
1.XML树在内存中完整存储,因此可以直接修改其数据结构.
2.可以通过该解析器随时访问XML树中的任何一个节点.
3.DOM解析器的API在使用上也相对比较简单.
缺点:
如果XML文档体积比较大时,将文档读入内存是非消耗系统资源的.
SAX解析
优点:
SAX 对内存的要求比较低,因为它让开发人员自己来决定所要处理的标签.特别是当开发人员只需要处理文档中包含的部分数据时,SAX 这种扩展能力得到了更好的体现.
缺点:
用SAX方式进行XML解析时,需要顺序执行,所以很难访问同一文档中的不同数据.此外,在基于该方式的解析编码程序也相对复杂.
使用场景:
对于含有数据量十分巨大,而又不用对文档的所有数据行遍历或者分析的时候,使用该方法十分有效.该方法不将整个文档读入内存,而只需读取到程序所需的文档标记处即可.
Xmlpull解析
android SDK提供了xmlpullapi,xmlpull和sax类似,是基于流(stream)操作文件,后者根据节点事件回调开发者编写的处理程序.因为是基于流的处理,因此xmlpull和sax都比较节约内存资源,不会像dom那样要把所有节点以对象树的形式展现在内存中.xmpull比sax更简明,而且不需要扫描完整个流.
Jar和aar的区别
Jar包里面只有代码,aar里面不光有代码还包括资源文件,比如 drawable 文件,xml资源文件。对于一些不常变动的 Android Library,我们可以直接引用 aar,加快编译速度。
Android为每个应用程序分配的内存大小是多少
老版一开始是16M,后面是24M,现在一般能给100-200M,可以用largeHeap申请更多内存
更新UI的方式
- Activity.runOnUiThread(Runnable)
- View.post(Runnable),View.postDelay(Runnable,long)(在当前操作视图UI线程添加队列)
- Handler
- AsyncTask
- Rxjava(这是什么?)
- LiveData
ContentProvider使用方法
进行跨进程通信,实现进程间的数据交互和共享。通过Context 中 getContentResolver() 获得实例,通过 Uri匹配进行数据的增删改查。ContentProvider使用表的形式来组织数据,无论数据的来源是什么,ConentProvider 都会认为是一种表,然后把数据组织成表格。
Thread、AsyncTask、IntentService的使用场景与特点
- Thread独立于Activity,当Activity finish后,如果没有主动停止Thread或者run方法没有执行完,其回一直执行下去
- AsyncTask封装了两个线程池和一个Handler,其必须在UI线程中创建,一个任务实例只允许执行一次,执行多次会抛出异常,一般用于网络请求或简单数据处理
- IntentService处理异步请求,实现多线程,在onHandleIntent中处理耗时操作,多个耗时任务会依次执行,执行完毕自动结束
Merge和ViewStub的作用
Merge: 减少视图层级,可以删除多余的层级。
merge:merge是一个特殊的标签,用于在布局文件中优化视图层次结构。通常,在编写布局文件时,我们需要使用一些容器布局(如LinearLayout、RelativeLayout等)来组织和嵌套视图。然而,这些容器布局本身不会渲染任何视图,仅用于组织和定位子视图。这样一来,在视图层次结构中添加了额外的布局容器,会导致层次结构变得复杂,影响性能。
为了解决这个问题,可以使用
merge标签,它会告诉布局解析器将其子视图直接添加到父视图中,而不会创建额外的布局容器。这样可以减少视图层次结构的深度,提高布局文件的加载和渲染效率。ViewStub: 按需加载,减少内存使用量、加快渲染速度、不支持 merge 标签。
ViewStub:ViewStub是一个轻量级的视图占位符,用于在布局中延迟加载视图。它允许我们在布局文件中定义一个占位符视图,实际的视图内容可以在需要时进行延迟加载。
使用
ViewStub可以在布局中预留一个位置,当需要显示相应的视图时,可以通过调用ViewStub.inflate()方法来动态加载视图并替换占位符。Activity的startActivity和其他context的startActivity区别是什么?
(1)、从Activity中启动新的Activity时可以直接mContext.startActivity(intent)就好
1
2
3
4
5
6
7
8public class MainActivity extends Activity {
// ...
public void startNewActivity() {
Intent intent = new Intent(MainActivity.this, NewActivity.class);
startActivity(intent);
}
}(2)、如果从其他Context(Service,BroadCastReceiver)中启动Activity则必须给intent设置Flag:
Intent.FLAG_ACTIVITY_NEW_TASK:将新Activity放入一个新的任务栈中。Intent.FLAG_ACTIVITY_CLEAR_TASK:在启动新Activity之前清除任务栈中的所有Activity。Intent.FLAG_ACTIVITY_CLEAR_TOP:如果目标Activity已经在任务栈中存在,则将其上方的Activity全部移除。Intent.FLAG_ACTIVITY_SINGLE_TOP:如果目标Activity已经在栈顶,不会重新创建实例,而是调用其onNewIntent()方法。
1
2
3
4
5
6
7
8
9public class MyService extends Service {
// ...
public void startNewActivity() {
Intent intent = new Intent(getApplicationContext(), NewActivity.class);
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
startActivity(intent);
}
}怎么在Service中创建Dialog对话框
1.在我们取得Dialog对象后,需给它设置类型,即:
dialog.getWindow().setType(WindowManager.LayoutParams.TYPE_SYSTEM_ALERT)2.在Manifest中加上权限:
<uses-permission android:name="android.permission.SYSTEM_ALERT_WINOW" />Asset目录与res目录的区别
assets:不会在 R 文件中生成相应标记,存放到这里的资源在打包时会打包到程序安装包中。(通过 AssetManager 类访问这些文件)
res:会在 R 文件中生成 id 标记,资源在打包时如果使用到则打包到安装包中,未用到不会打入安装包中。
res/anim:存放动画资源。
res/raw:和 asset 下文件一样,打包时直接打入程序安装包中(会映射到 R 文件中)
如何提升Activity启动速度?
- 避免在OnCreate中执行耗时操作
- 渲染页面时,将View细分,放在AsyncTask中逐步显示,用Handler更好,这样用户可以看到界面的逐步渲染,而不是黑屏到界面突然出现,如果有动画更好
- 合理使用多线程
- 提高Adapter和AdapterView的效率
- 优化布局文件
Handler机制

- message:消息
- MessageQueue:消息队列,looper有一个消息队列,物理结构上是一个单链表,消息不断被加入和读取
- Looper:消息循环器,负责关联线程以及消息的分发,在该线城下从MessageQueue获取Message获取Message,分发给Handler,调用Looper.loop()即启动Looper,并且不断执行next()方法,直到调用Looper.quit()
整个消息的循环流程还是比较清晰的,具体说来:
- 1、Handler通过sendMessage()发送消息Message到消息队列MessageQueue。
- 2、Looper通过loop()不断提取触发条件的Message,并将Message交给对应的target handler来处理。
- 3、target handler调用自身的handleMessage()方法来处理Message。
有很多事情都是通过C++完成的,MessageQueue是Java层和C++层沟通的桥梁,MessageQueue的核心功能实际上是使用Native C++完成的
Handler可能引发内存泄漏
Handler允许发送延时消息,在延时期间如果用户关闭了Activity,那么该Activity将会泄露,因为这个延迟消息持有Handler,而Handler又持有Activity
解决:将 Handler 定义成静态的内部类,在内部持有 Activity 的弱引用,并在Acitivity的onDestroy()中调用handler.removeCallbacksAndMessages(null)及时移除所有消息。
为什么我们可以直接在主线程里面使用Handler,而不需要创建Looper?
在Android中,主线程(也称为UI线程)已经预先创建了一个Looper对象,并在应用启动时自动初始化了消息循环。因此,在主线程中可以直接使用Handler对象,而无需显式地创建Looper。
当应用启动时,Android系统会在主线程上自动调用
Looper.prepareMainLooper()方法创建主线程的Looper对象,并将其存储在ThreadLocal中。随后,调用Looper.loop()方法启动主线程的消息循环。(主线程的Looper不允许退出,如果退出,那么App就要挂)
Handler 里藏着的 Callback 能干什么?
Handler.Callback 有优先处理消息的权利 ,当一条消息被 Callback 处理并拦截(返回 true),那么 Handler 的 handleMessage(msg) 方法就不会被调用了;如果 Callback 处理了消息,但是并没有拦截,那么就意味着一个消息可以同时被 Callback 以及 Handler 处理。
创建 Message 实例的最佳方式
为了节省开销,Android 给 Message 设计了回收机制,所以我们在使用的时候尽量复用 Message ,减少内存消耗:
- 通过 Message 的静态方法 Message.obtain();
- 通过 Handler 的公有方法 handler.obtainMessage()。(本质上还是调用的Message.obtain())
子线程里弹 Toast 的正确姿势
- 创建一个Runnable对象,通过主线程的Handler发送到主线程,由主线程来显示Toast
- 在子线程中先preperLoop并且启动,并且创建Handler,直接在子线程中显示
妙用Looper
子线程做耗时的操作,最后更新UI则通过主线程的Handler Post到主线程
利用 Looper 判断当前线程是否是主线程:有时候我们需要根据当前线程是主线程还是子线程来做一些不同的处理。通过 Looper 的
getMainLooper()方法可以获取到主线程的 Looper 对象。我们可以利用这个特性来判断当前线程是否是主线程。1
2
3
4
5if (Looper.myLooper() == Looper.getMainLooper()) {
// 当前线程是主线程
} else {
// 当前线程是子线程
}
主线程的死循环一直运行是不是特别消耗CPU资源呢?
并不是,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质是同步I/O,即读写是阻塞的。所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
Handler postDelay这个延迟是怎么实现的?
Handler并不是等到延迟时间结束再将消息发送给Queue,而是直接发送,只不过附带了一个时间戳,MessageQueue会根据时间戳将消息进行排序,顺序唤醒
程序A能否接受到程序B的广播?
能,使用全局的BroadCastRecevier能进行跨进程通信,但是注意它只能被动接收广播。此外,LocalBroadCastRecevier只限于本进程的广播间通信。
分页加载数据
分页加载就是一页一页加载数据,当滑动到底部、没有更多数据加载的时候,我们可以手动调用接口,重新刷新RecyclerView。
Gson解析json时javabean的定义规则
类的字段名需要与JSON中的键名保持一致。Gson通过反射来匹配字段名和键名进行数据绑定。如果字段名和键名不一致,可以使用注解
@SerializedName("json_key")来显式指定JSON中的键名。类需要提供一个无参构造函数。Gson在解析JSON时会使用无参构造函数来创建JavaBean对象,并通过反射设置字段的值。如果没有提供无参构造函数,可以自定义带参数的构造函数,但同时也需要提供无参构造函数。
类的字段需要为私有(private)访问权限,并提供公共的 getter 和 setter 方法。Gson通过调用getter和setter方法来获取和设置字段的值。
类可以使用注解
@Expose来标记需要进行JSON序列化和反序列化的字段。如果没有使用@Expose注解,Gson默认会处理所有的字段。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import com.google.gson.Gson;
import com.google.gson.annotations.SerializedName;
public class Person {
private String name;
private int age;
public Person() {
// 无参构造函数
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class Main {
public static void main(String[] args) {
String json = "{\"name\":\"John Doe\",\"age\":30,\"email\":\"[email protected]\"}";
Gson gson = new Gson();
Person person = gson.fromJson(json, Person.class);
System.out.println("Name: " + person.getName());
System.out.println("Age: " + person.getAge());
}
}
json解析方式的两种区别?
- SDK提供JsonObject和JsonArray的解析方式
- Gson通过fromJson()实现对象的反序列化(即将json串转换为对象类型)通过toJson()实现对象的序列化
- Gson提供通过javaBean的方式进行解析,总体上更加灵活多样
线程池
Android中线程池是通过配置ThreadPoolExecutor来实现的,最常见的四类线程池是FixedThreadPool、CacheThreadPool、SingleThreadPool和ScheduledThreadPool
- FixedThreadPool:固定线程池,线程数是固定的,所有线程都处于活动状态,也不会被回收,相应较快
- CacheThreadPool:有很大的最大线程数,有空闲线程的概念,空闲时间过长会被线程池回收,适合处理大量执行时间短的任务
- ScheduledThreadPool:核心线程数固定,非核心线程空闲时会被回收,适合于执行有固定周期的重复任务
- SingleThreadPool:只有一个核心线程,不用考虑多线程的问题,适合需要顺序执行的任务
什么是内存泄漏?内存泄漏是如何产生的?如何查找和分析内存泄漏?
内存泄漏(Memory Leak)指的是在程序中分配的内存空间无法被回收和释放,导致内存资源的浪费和耗尽。当内存泄漏发生时,程序会持续占用内存,导致系统性能下降,甚至可能导致应用崩溃。
内存泄漏发生的原因:
- 资源对象没有关闭或者没有正确关闭:资源型对象往往使用了一些缓冲,这种缓冲不仅存在JVM之内,还存在于JVM之外,因此简单的将他们的引用置为null并不能正确的释放资源,当资源对象不再使用时,应当调用它们提供的销毁接口
- 构造Adapter时,没有使用缓存的convertView:这个没有看懂
- Bitmap对象不再使用时调用recycle()释放内存
- Activity无法释放导致内存泄漏:如果一个对象的生命周期长于一个Activity,那么就不要将Activity的Context,改传Application的Context
- 注册没有取消造成内存泄漏:一些Android程序可能引用我们的Android程序,即使我们的Android程序已经结束,但是别的引用程序仍然还对我们的Android程序的某个对象的引用,这将导致无法进行垃圾回收,比如调用RegisterReceiver后未调用UnregisterReceiver
- 集合中对象没清理造成内存泄露:我们通常把一些对象的引用加入到了集合中,当我们不需要该对象时,并没有把它的引用从集合中清理掉,这样这个集合就会越来越大。如果这个集合是static的话,那情况就更严重了。
查找内存泄漏
- 使用MemoryProfiler,运行程序后如果收到内存泄漏报警则点击查看HeapDump
- MemoryAnalyzer Tool(MAT),运行程序然后退出,手动触发GC,然后使用adb shell dumpsys meminfo packagename -d命令查看退出界面后Objects下的Views和Activities数目是否为0,如果不是则通过Leakcanary检查可能存在内存泄露的地方,最后通过MAT分析,如此反复,改善满意为止。
- 对比hprof文件,检测出复杂情况下的内存泄露
类初始化的顺序
- 静态成员变量初始化
- 静态代码块
- 实例成员变量初始化
- 构造代码块
- 构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class InitializationExample {
// 静态成员变量
private static int staticVariable = initializeStaticVariable();
// 静态代码块
static {
System.out.println("静态代码块被执行了");
}
// 实例成员变量
private int instanceVariable = initializeInstanceVariable();
// 构造代码块
{
System.out.println("构造代码块被执行了");
}
// 构造函数
public InitializationExample() {
System.out.println("构造函数被执行了");
}
// 静态成员变量初始化方法
private static int initializeStaticVariable() {
System.out.println("静态成员变量初始化");
return 10;
}
// 实例成员变量初始化方法
private int initializeInstanceVariable() {
System.out.println("实例成员变量初始化");
return 20;
}
public static void main(String[] args) {
InitializationExample example = new InitializationExample();
}
}JSON的结构?
json是一种轻量级的数据交换格式, json简单说就是对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
1、对象:对象表示为“{}”扩起来的内容,数据结构为 {key:value,key:value,…}的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是 数字、字符串、数组、对象几种。
2、数组:数组在json中是中括号“[]”扩起来的内容,数据结构为 [“java”,”javascript”,”vb”,…],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。 经过对象、数组2种结构就可以组合成复杂的数据结构了。
Android为什么引入parcelabel?
在Android开发中,我们经常需要在不同组件(如Activity、Fragment、Service)之间传递数据对象。最常见的方式是使用Intent来传递数据,但是Intent使用Java的序列化(Serializable)机制来实现对象的传递。虽然Serializable是一种简单易用的方式,但是在性能方面存在一些问题:
- 序列化和反序列化的过程需要大量的I/O操作,会对性能产生负面影响。
- 序列化的结果是一个字节数组,会占用较大的内存空间。
- 序列化和反序列化过程中会产生大量的临时对象,增加了垃圾回收的压力。
为了解决这些问题,Android引入了Parcelable接口。Parcelable接口提供了一种高效的序列化机制,能够更快速地将对象序列化为字节流,并在需要时进行反序列化。相对于Serializable,Parcelable具有以下优势:
- 性能更好:Parcelable使用了更高效的序列化和反序列化机制,避免了大量的I/O操作和临时对象的创建,因此比Serializable更快速和高效。
- 内存占用更少:Parcelable序列化的结果是一个较小的字节数组,相比Serializable占用的内存更少,减轻了内存压力。
- 更精确地控制序列化过程:Parcelable允许开发人员对序列化的过程进行更精确地控制,可以选择序列化和反序列化对象的哪些部分,从而提高效率。
ViewPager使用细节,如何设置成每次只初始化当前的Fragment,其他的不初始化(提示:Fragment懒加载)?
自定义一个 LazyLoadFragment 基类,利用 setUserVisibleHint 和 生命周期方法,通过对 Fragment 状态判断,进行数据加载,并将数据加载的接口提供开放出去,供子类使用。然后在子类 Fragment 中实现 requestData 方法即可。这里添加了一个 isDataLoaded 变量,目的是避免重复加载数据。考虑到有时候需要刷新数据的问题,便提供了一个用于强制刷新的参数判断。(这个方法已经过时了)
在使用ViewPager时,可以通过使用FragmentPagerAdapter或是FragmentStatePagerAdapter来控制Fragment的初始化行为。以下是一种设置ViewPager每次只初始化当前Fragment的方法:
- 创建一个自定义的PagerAdapter类,继承自FragmentPagerAdapter或是FragmentStatePagerAdapter。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public class CustomPagerAdapter extends FragmentPagerAdapter {
private List<Fragment> fragments;
public CustomPagerAdapter(FragmentManager fragmentManager, List<Fragment> fragments) {
super(fragmentManager);
this.fragments = fragments;
}
public Fragment getItem(int position) {
return fragments.get(position);
}
public int getCount() {
return fragments.size();
}
public CharSequence getPageTitle(int position) {
// 返回每个Fragment对应的标题(可选)
return "Fragment " + (position + 1);
}
public Object instantiateItem(ViewGroup container, int position) {
// 在这里通过position判断当前显示的Fragment,只初始化当前Fragment
if (position == getCurrentFragmentPosition()) {
return super.instantiateItem(container, position);
} else {
// 返回一个空的Fragment作为占位符
return new Fragment();
}
}
private int getCurrentFragmentPosition() {
// 根据自己的逻辑获取当前显示的Fragment的位置
return 0;
}
}- 在创建ViewPager时,使用自定义的PagerAdapter。
1
2
3
4
5
6
7
8ViewPager viewPager = findViewById(R.id.viewPager);
List<Fragment> fragments = new ArrayList<>();
fragments.add(new Fragment1());
fragments.add(new Fragment2());
fragments.add(new Fragment3());
CustomPagerAdapter pagerAdapter = new CustomPagerAdapter(getSupportFragmentManager(), fragments);
viewPager.setAdapter(pagerAdapter);上述代码中,自定义的PagerAdapter类重写了
instantiateItem()方法。在该方法中,通过判断当前显示的Fragment的位置,只对当前Fragment进行初始化,而对其他Fragment返回一个空的Fragment作为占位符。你可以根据自己的逻辑来确定当前显示的Fragment的位置。这样设置后,ViewPager每次只会初始化当前显示的Fragment,其他的Fragment将不会被初始化,从而提高了性能和效率。
注意:使用FragmentStatePagerAdapter时,系统会销毁不再需要的Fragment,因此在
instantiateItem()方法中,可以返回一个空的Fragment作为占位符。而对于FragmentPagerAdapter,可以通过重写destroyItem()方法来实现类似的效果。希望这个答案对你有所帮助!如果你有其他问题,请随时提问。
如何简化Parcelabel的使用?
kotlin可以使用Parcelize注解简化Parcelable的书写
Android扩展插件现在包含一个实现了Parcelable的自动生成器。在主构造函数中声明序列化的属性并添加一个@Parcelize注解,生成器就会自动创建writeToParcel()/ createFromParcel()方法
1
2
data class Student(val id: String, val name: String, val grade: String) : Parcelable使用bitmap时应当注意什么?
选择合适的图片规格
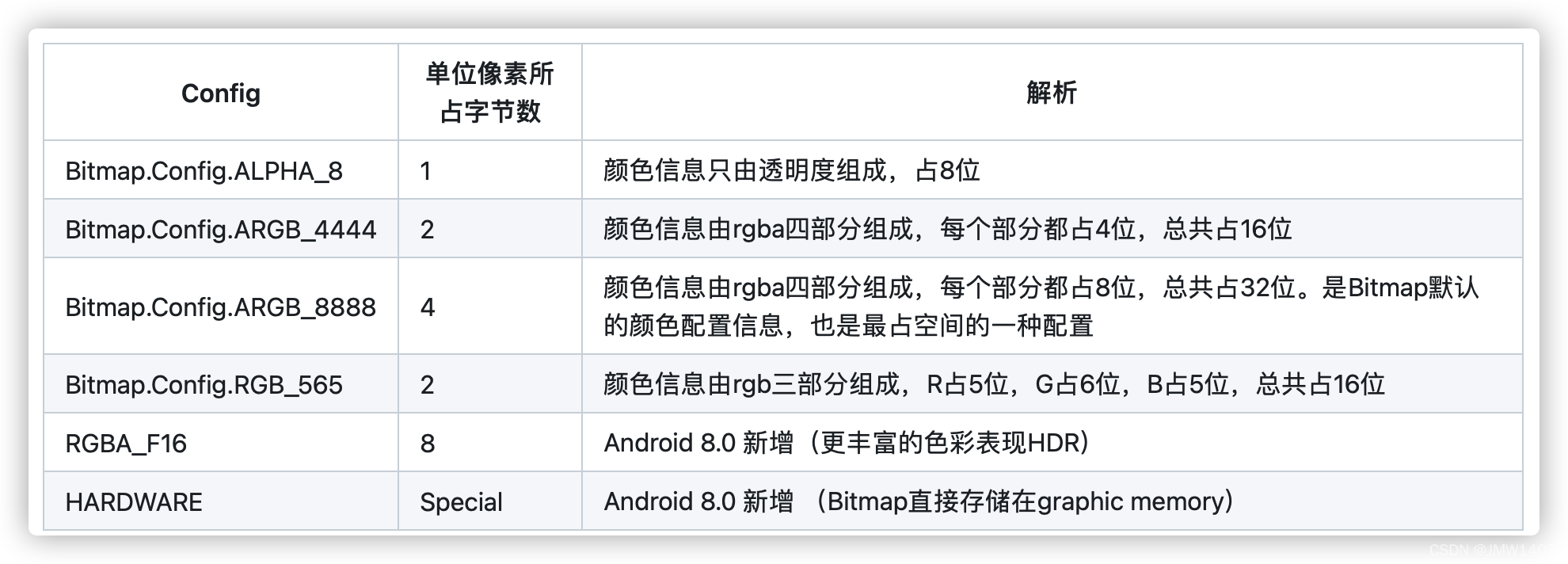
降低采样率
可以通过比较要显示的大小和图片的实际大小选择一个合适的采样率,降低图片的内存占用
复用内存
即,通过软引用(内存不够的时候才会回收掉),复用内存块,不需要再重新给这个bitmap申请一块新的内存,避免了一次内存的分配和回收,从而改善了运行效率。
使用recycle()方法回收内存
压缩图片:Jpeg,Png,Webp
OOM是否可以Try Catch?
有一种情况可以:
Try语句块中声明了巨大的对象,比如位图,导致OOM,在catch语句中,可以尝试释放这些大的对象,解决OOM
但是我们推荐使用软引用、弱引用、硬盘缓存来处理这种问题
如果OOM的原因不是这些大对象,那么Catch语句将继续抛出OOM
多进程
一般来说,Android应用多进程有三个好处。
1)我们知道Android系统对每个应用进程的内存占用是有限制的,而且占用内存越大的进程,通常被系统杀死的可能性越大。让一个组件运行在单独的进程中,可以减少主进程所占用的内存,降低被系统杀死的概率.
2)如果子进程因为某种原因崩溃了,不会直接导致主程序的崩溃,可以降低我们程序的崩溃率。
3)即使主进程退出了,我们的子进程仍然可以继续工作,假设子进程是推送服务,在主进程退出的情况下,仍然能够保证用户可以收到推送消息。使用:在配置文件中设置process,但是注意一旦使用多进程会有多种问题,比如Application重复创建的问题、静态变量失效的问题、多个进程资源共享困难的问题
Canvas.save()与Canvas.restore()的调用时机
save:用来保存Canvas的状态。save之后,可以调用Canvas的平移、放缩、旋转、错切、裁剪等操作。
restore:用来恢复Canvas之前保存的状态。防止save后对Canvas执行的操作对后续的绘制有影响。
save和restore要配对使用(restore可以比save少,但不能多),如果restore调用次数比save多,会引发Error。save和restore操作执行的时机不同,就能造成绘制的图形不同。
android数据库迁移(修改表,增加表和删除表不用改version)
SQLite
SQLiteHelper中有一个onCreate()和onUpgrade()函数,当用户尝试访问数据库时,如果数据库版本更新了,就会跑去调用onUpgrade()
在onUpgrade中,判断老版本,然后升级到新版本,升级的过程是
- 将现在的表重命名位临时表
- 创建新的表
- 临时表的数据导入到新表
- 删除临时表
升级过程应该包裹在 db.beginTransaction(); 和 db.setTransactionSuccessful(); 之间,这样过程中出错数据库可以自动回滚
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
switch (newVersion) {
case 2:
db.beginTransaction();
db.execSQL(CREATE_TEMP_BOOK);
db.execSQL(CREATE_BOOK);
db.execSQL(INSERT_DATA);
db.execSQL(DROP_BOOK);
db.setTransactionSuccessful();
db.endTransaction();
break;
}跨版本升级既可以给每种版本之间的升级写逻辑(要写死),也可以直接链式升级(如果用户版本比较低会让用户等比较久)
Room的数据库迁移
较高版本的Room支持自动迁移,但是比较复杂的情况仍然需要手动迁移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Database class before the version update.
abstract class AppDatabase : RoomDatabase() {
...
}
// Database class after the version update.
abstract class AppDatabase : RoomDatabase() {
...
}删除或重命名表等架构更改不明确的操作需要通过AutoMigrationSpec为Room指出数据库迁移时的配置
Spec有四种注解:
@DeleteTable(tableName)@RenameTable(fromTableName, toTableName)@DeleteColumn(tableName, columnName)@RenameColumn(tableName, fromColumnName, toColumnName)
1
2
3
4
5
6
7
8
9
10
11
12
13/* Copyright 2020 Google LLC.
SPDX-License-Identifier: Apache-2.0 */
abstract class DoggosDatabase : RoomDatabase { }注意exportSchema一定要是true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
abstract class DoggosDatabase : RoomDatabase() {
class DoggosAutoMigration1: AutoMigrationSpec { }
class DoggosAutoMigration2 : AutoMigrationSpec {}
}手动迁移:如果怎么搞都搞不好,就用手动迁移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15val MIGRATION_1_2 = object : Migration(1, 2) {
override fun migrate(database: SupportSQLiteDatabase) {
database.execSQL("CREATE TABLE `Fruit` (`id` INTEGER, `name` TEXT, " +
"PRIMARY KEY(`id`))")
}
}
val MIGRATION_2_3 = object : Migration(2, 3) {
override fun migrate(database: SupportSQLiteDatabase) {
database.execSQL("ALTER TABLE Book ADD COLUMN pub_year INTEGER")
}
}
Room.databaseBuilder(applicationContext, MyDb::class.java, "database-name")
.addMigrations(MIGRATION_1_2, MIGRATION_2_3).build()
编译期注解与运行期注解(这个好难)
运行期注解利用反射获取信息,比较消耗性能,对应@Retention(RetentionPolicy.RUNTIME)这个反射是一个循环类型的,时间开销很大,所以一般都喜欢写编译期注解
编译期注解使用APT和Javapoet实现,对应@Retention(RetentionPolicy.CLASS)
bitmap和recycler()
2.3.3即以下应该在不使用位图时调用recycle方法,释放位图占用的内存,避免OOM,这个时代,bitmap本身放在栈中,引用放在堆中,因此需要手动调用recycle(),在3.0以上后整个bitmap都被放到了堆里面,于是整个创建和回收都被交给了GC,并且引入了inbitmap,位图删除后还会持有一个软引用,后面要用如果位图还没有被释放就能直接用位图了
Android官方推荐使用Glide库加载和处理位图,Glide提供许多复杂操作的抽象
强引用置为null会不会立刻被回收?
不会,GC试运行在后台线程中的,只有当用户线程运行到安全点或是安全区域时才会启动对象引用关系的扫描,扫描完成也不会立刻释放,因为有一些对象的引用是可以恢复的,只有确定对象的引用无法恢复后才会正式回收对象
Bundle传递对象为什么要序列化
序列化表示将一个对象转换成可存储或可传输的状态,序列化的原因基本都是三种情况:
- 永久性保存对象,保存对象的字节序列到本地文件中
- 对象在网络中传递
- 对象在IPC(不同进程间)传递
广播传递数据是否有限制
Intent在传递数据时是有大小限制的,大约限制在1MB之内,你用Intent传递数据,实际上走的是跨进程通信(IPC),跨进程通信需要把数据从内核copy到进程中,每一个进程有一个接收内核数据的缓冲区,默认是1M;如果一次传递的数据超过限制,就会出现异常。
不同厂商表现不一样有可能是厂商修改了此限制的大小,也可能同样的对象在不同的机器上大小不一样。
传递大数据,不应该用Intent;考虑使用ContentProvider或者直接匿名共享内存。简单情况下可以考虑分段传输。
硬件加速
硬件加速就是运用GPU优秀的运算能力来加快渲染的速度,而通常的基于软件的绘制渲染模式是完全利用CPU来完成渲染。
android api 11开始支持硬件加速,14开始默认开启硬件加速
对于自定义View可能会出现硬件加速不兼容的情况,这是需要手动关闭硬件加速
关闭或开启硬件加速可以在应用、Activity、窗口、视图四个层面进行控制
应用级别
1
2<application android:hardwareAccelerated="true" ...>
Activity级别
1
2
3
4
5<application android:hardwareAccelerated="true">
<activity ... />
<activity android:hardwareAccelerated="false" />
</application>窗口级别 启用(官方文档说现在不行了)
1
2
3
4
5window.setFlags(
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED
)视图级别 SOFTWARE停用加速 HARDWARE启用加速
1
2myView.setLayerType(View.LAYER_TYPE_SOFTWARE, null)
硬件加速也有内存开销:硬件加速的消耗问题,因为是使用OpenGL,需要把系统中OpenGL加载到内存中,OpenGL API调用就会占用8MB,而实际上会占用更多内存,并且使用了硬件必然增加耗电量了
硬件加速的优势还有display list的设计,使用这个我们不需要每次重绘都执行大量的代码,基于软件的绘制模式会重绘脏区域内的所有控件,而display只会更新列表,然后绘制列表内的控件。
CPU更擅长复杂逻辑控制,而GPU得益于大量ALU和并行结构设计,更擅长数学运算。
ContentProvider权限管理,似懂非懂
Fragment状态保存
1、Activity的状态保存, 在Activity的onSaveInstanceState()里, 调用了FragmentManger的saveAllState()方法, 其中会对mActive中各个Fragment的实例状态和View状态分别进行保存.
2、FragmentManager还提供了public方法: saveFragmentInstanceState(), 可以对单个Fragment进行状态保存, 这是提供给我们用的。
3、FragmentManager的moveToState()方法中, 当状态回退到ACTIVITY_CREATED, 会调用saveFragmentViewState()方法, 保存View的状态.
在Activity中创建一个Thread和在Service中创建一个Thread的区别
在Activity中被创建:该Thread的就是为这个Activity服务的,完成这个特定的Activity交代的任务,主动通知该Activity一些消息和事件,Activity销毁后,该Thread也没有存活的意义了。
在Service中被创建:这是保证最长生命周期的Thread的唯一方式,只要整个Service不退出,Thread就可以一直在后台执行,一般在Service的onCreate()中创建,在onDestroy()中销毁。所以,在Service中创建的Thread,适合长期执行一些独立于APP的后台任务,比较常见的就是:在Service中保持与服务器端的长连接
计算bitmap内存大小,如何避免bitmap产生内存溢出
Bitamp 占用内存大小 = 宽度像素 x (inTargetDensity / inDensity) x 高度像素 x (inTargetDensity / inDensity)x 一个像素所占的内存
注:这里inDensity表示目标图片的dpi(放在哪个资源文件夹下),inTargetDensity表示目标屏幕的dpi,所以你可以发现inDensity和inTargetDensity会对Bitmap的宽高进行拉伸,进而改变Bitmap占用内存的大小。
在Bitmap里有两个获取内存占用大小的方法。
getByteCount():API12 加入,代表存储 Bitmap 的像素需要的最少内存。 getAllocationByteCount():API19 加入,代表在内存中为 Bitmap 分配的内存大小,代替了 getByteCount() 方法。 在不复用 Bitmap 时,getByteCount() 和 getAllocationByteCount 返回的结果是一样的。在通过复用 Bitmap 来解码图片时,那么 getByteCount() 表示新解码图片占用内存的大 小,getAllocationByteCount() 表示被复用 Bitmap 真实占用的内存大小(即 mBuffer 的长度)。
避免内存溢出:
- bitmapFactory 图片压缩
- 改变像素类型
- inPurgeable 让系统可以回收bitmap的内存
如何向用户推送应用更新?
- 通过接口获取最新版本号
- 和本地版本比较
- 显示更新提示
- 下载APK并安装
全量发布:直接把新版本推给全部用户,有bug测试组切腹自尽
灰度发布:发一点点,有bug打补丁(AB test策略)
为什么Android要引入签名机制?
- 验证身份:开放商可能用相同的package name来混淆替换已经安装的程序,签名机制可以保证签名不同的包不会被替换
- 避免被替换:签名利用摘要算法避免应用程序包被修改
- 系统权限控制:Android的权限模型依赖于应用的签名。系统会根据应用的签名来确定应用所具有的权限。如果应用的签名与系统中预先分发的权限声明相匹配,应用将被授予相应的权限。这样可以防止未经授权的应用获取敏感权限。
- 应用更新验证:当应用程序更新时,系统会验证新版本的应用是否使用相同的签名。只有相同签名的应用才能被视为同一个应用的更新版本。这样可以防止恶意开发者发布伪装成合法应用的恶意更新。
通过Gradle配置多渠道包
1
2
3
4
5
6
7
8android {
productFlavors {
xiaomi {}
baidu {}
wandoujia {}
_360 {} // 或“"360"{}”,数字需下划线开头或加上双引号
}
}执行./gradlew assembleRelease ,将会打出所有渠道的release包;
执行./gradlew assembleWandoujia,将会打出豌豆荚渠道的release和debug版的包;
执行./gradlew assembleWandoujiaRelease将生成豌豆荚的release包。
因此,可以结合buildType和productFlavor生成不同的Build Variants,即类型与渠道不同的组合。
activity和Fragment之间怎么通信,Fragment和Fragment怎么通信?
- Handler
- 广播
- 事件总线
- 接口回调
- bundle和setArguments(bundle)
Kotlin协程
MotionLayout
1
2
3
4
5
6
7
8var isOnSearch = false
// 监听搜索按钮点击事件
searchBar.setOnClickListener {
// 当搜索按钮被点击时,触发上升动画
homeMotion.transitionToState(R.id.end)
isOnSearch = true
// Log.i("gggg", "搜索框被点击")
}
计算机网络
HTTP协议
什么是HTTP协议?
从三个方面理解:协议、传输、超文本
HTTP 是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范(两个以上的参与者),以及相关的各种控制和错误处理方式(行为约定和规范)。
HTTP 协议是一个双向协议。数据虽然是在 A 和 B 之间传输,但允许中间有中转或接力。中间人遵从 HTTP 协议,只要不打扰基本的数据传输,就可以添加任意额外的东西。
「超文本」,它就是超越了普通文本的文本,它是文字、图片、视频等的混合体,最关键有超链接,能从一个超文本跳转到另外一个超文本。HTML 就是最常见的超文本了,它本身只是纯文字文件,但内部用很多标签定义了图片、视频等的链接,再经过浏览器的解释,呈现给我们的就是一个文字、有画面的网页了。
HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
HTTP常见的状态码

- 1xx:中间状态
- 2xx:OK
- 200 OK
- 204 OK,只是没有返回的Body
- 206 OK,返回了一部分数据
- 3xx:重定向
- 301 永久重定向,会将浏览器重定向
- 302 临时重定向,同上
- 304 重定向到缓存
- 4xx:存在错误
- 400 笼统的错误码
- 403 禁止访问
- 404 资源未找到
- 5xx:服务器出错
- 500 笼统的错误码
- 501 尚未实现的功能
- 502 网关错误,访问后端异常
- 503 服务器太忙无法响应请求
Http缓存原理
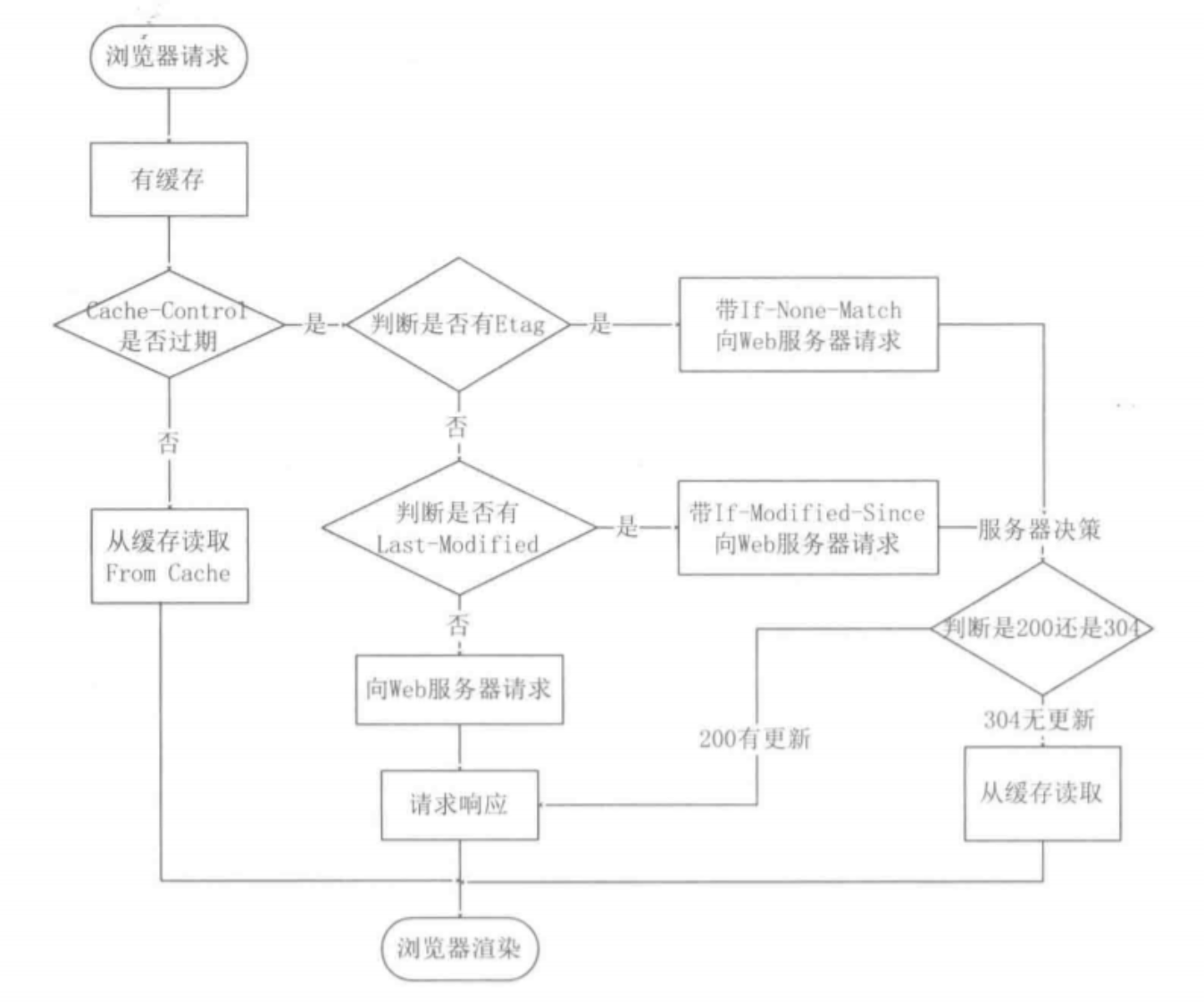
- 双方约定什么时候要重新请求:强制缓存
- Cache-Control 通过请求时间和服务器给出的时间,为资源计算一个过期时间
- Expire 服务器直接规定什么时候过期
- 如果需要重新请求,但是服务器觉得还可依据需用缓存:协商缓存
- Etag:服务器为资源文件生成一个唯一标识,提供给客户端,客户端请求时加上if-none-match,如果资源文件的etag没变,那么直接304
- Label-Modified:服务器告诉客户端资源文件请求时的最近一次修改时间,重新请求时带上if-modified-since,如果资源文件更新时间没有发生变化,那么304
- Etag比Label-Modified好用,因为
- 没修改文件,修改时间也会变,客户端就莫名其妙的重新请求了
- label-modified只能精确到秒级,一些文件的修改可能发生在秒内,导致无法被检测到
- 一些服务器不能很好地获取文件最后修改时间
- 双方约定什么时候要重新请求:强制缓存
Get与Post
按照Http标准设置的Get请求是安全且幂等的(不会修改服务器本身并且多次操作获得的结果一样),POST请求则不是
Http/1.1的特性
- 简单:报文header+body,header也是key-value形式,结构很简单
- 灵活且易于扩展:各种请求方法、URI/URL、状态码、头字段都可以由开发者自定义和扩充,http作为应用层协议,允许下层协议进行变化,比如添加TLS/SSL层、TCP改UDP
- 应用广泛和跨平台
Http/1.1的缺点
- Http本身无状态:这意味着Http协议本身不能持续识别用户,也无法识别相互关联的请求,一种可能的解决方案是使用cookie
- 数据裸奔:Http本身没有加密,所有信息都在互联网上裸奔
- 不安全:信息不加密、不验证对方的身份、不检查数据是否被中间人修改
Http/1.1性能及解决方案
关键:TCP/IP协议的耗时
长连接避免反复建立连接的时间开销
管道网络传输,客户端没收到回应就接着发请求,解决请求队头阻塞的问题(但是这个功能几乎没有被使用过)
队头阻塞:即使用了管道网络传输解决请求对头阻塞,响应对头阻塞也是无法解决的
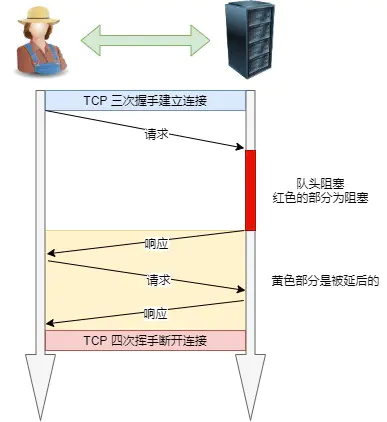
HTTP与HTTPS的区别
- HTTP TCP连接建立后直接开始传输,HTTPS在TCP请求建立后还要经历SSL/TLS握手过程,才会正式开始传输
- HTTP信息裸奔,HTTPS采用混合加密技术,保证数据安全
- HTTP默认端口为80,HTTPS默认端口443
- HTTPS协议要想CA请求证书,验证对方的身份
HTTPS如何保证安全
信息加密:采用混合加密技术保证信息安全
混合加密
- 在通信建立前采用非对称加密方式传递生成一个会话密钥
- 通信过程中使用会话密钥进行对称加密
身份校验:摘要算法+数字签名
摘要算法
发送方通过摘要算法(一种hash算法)计算出一个通信数据的指纹,一起发送给对方,对方收到后,也算出通信数据的一个指纹,然后与发过来的比较,如果不一样那就说明信息被篡改了
数字证书
为了避免hash值也被篡改,服务器向客户端颁发公钥,然后用自己的私钥给hash值加密,客户端收到后如果能用自己的密钥解开,就能证明是服务端发送的,然后再验证指纹,如果指纹也是一样的,就能证明内容没有被篡改
但是客户端得到的公钥也可能是中间人伪造的,因此我们需要一个CA来帮助我们验证
服务器会将自己的公钥注册到CA,而CA会颁发一个数字证书给服务器,这个数字证书中有一个CA计算得到并且通过CA私钥加密的hash值,可以被CA的公钥解密,而CA的公钥已经提前内置到浏览器或操作系统里(所以不要用来路不明的浏览器,里面可能有来路不明的CA公钥),当建立HTTPS连接时,服务器将自己的数字证书发给客户端,客户端使用内置的公钥解密,如果能解密得到的hash值与获得的证书算出的hash值相同·,说明数字证书没被篡改,从而获得服务器的公钥,然后客户端可以使用这个公钥加密并发送数据到服务端
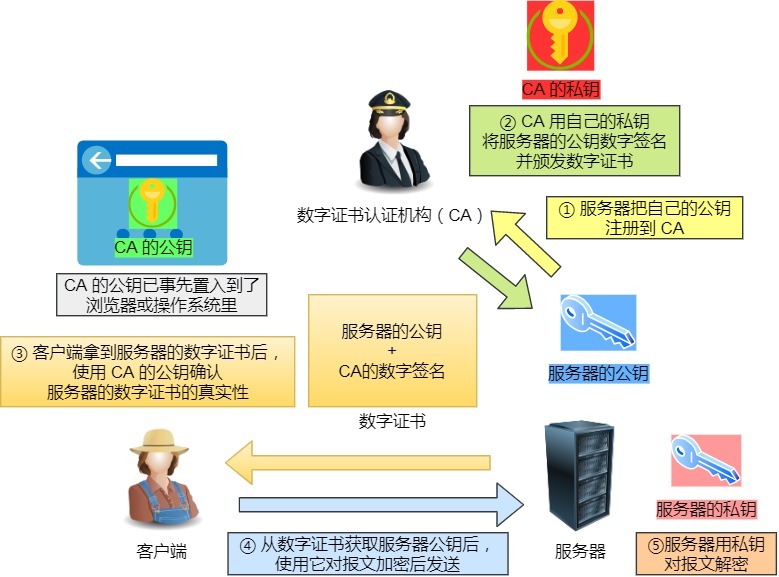
完整的基于RSA算法的TLS握手与HTTPS建立过程
- 客户端索要服务器数字证书,验证后获得的公钥
- 双方协商生产会话密钥
- 双方采用会话秘钥加密通信
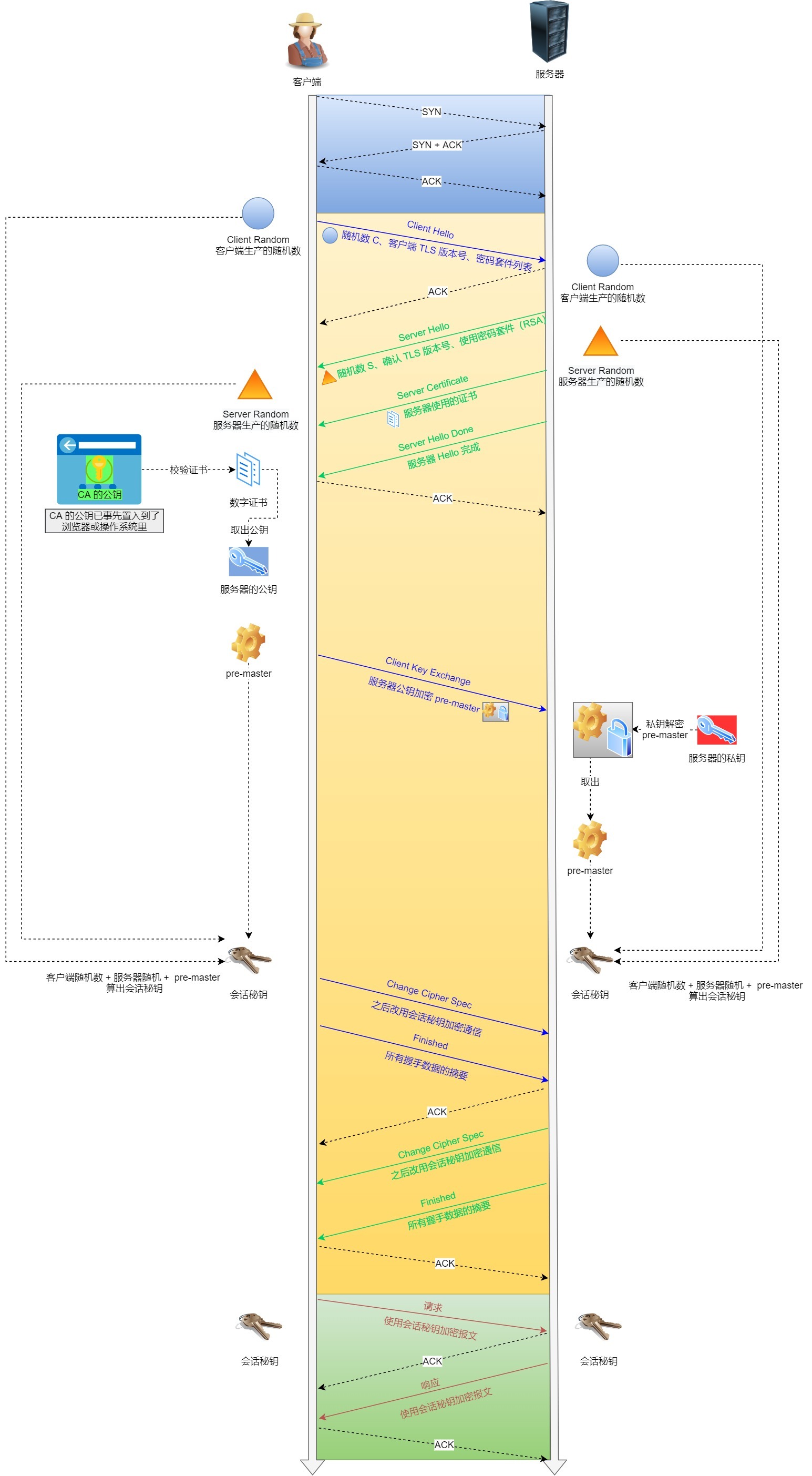
完整过程:
ClientHello
客户端向服务器发起加密请求,发送的信息包括:
- 客户端支持的TLS版本(如果服务器不支持直接拜拜)
- 客户端生产的随机数
- 客户端支持的密码套件列表,如RSA加密算法(如果加密算法不支持也拜拜)
ServerHello
服务器收到请求后发出响应
- 确认TLS协议版本
- 服务器生产的随机数
- 确认密码套件列表
- 服务器的数字证书
客户端回应
首先客户端会验证服务器发来的数字证书,没问题就取出解密后的公钥
- 一个被服务器公钥加密的随机数
- 加密算法改变通知:接下来所有的通信都将使用会话密钥
- 握手结束通知:将之前所有通信的数据做一个摘要,供服务端检验
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
服务器最后的回应
- 加密算法改变通知
- 前面所有通信的摘要,供客户端校验
缺点:RSA算法的HTTPS存在“前向安全问题”,即一旦服务端的私钥泄露,客户端通过公钥加密的随机数就会泄露,从而导致会话秘钥泄露,最终导致整个通讯裸奔
为了解决这一问题,便有了ECDHE密钥协商算法
CA颁发证书的过程
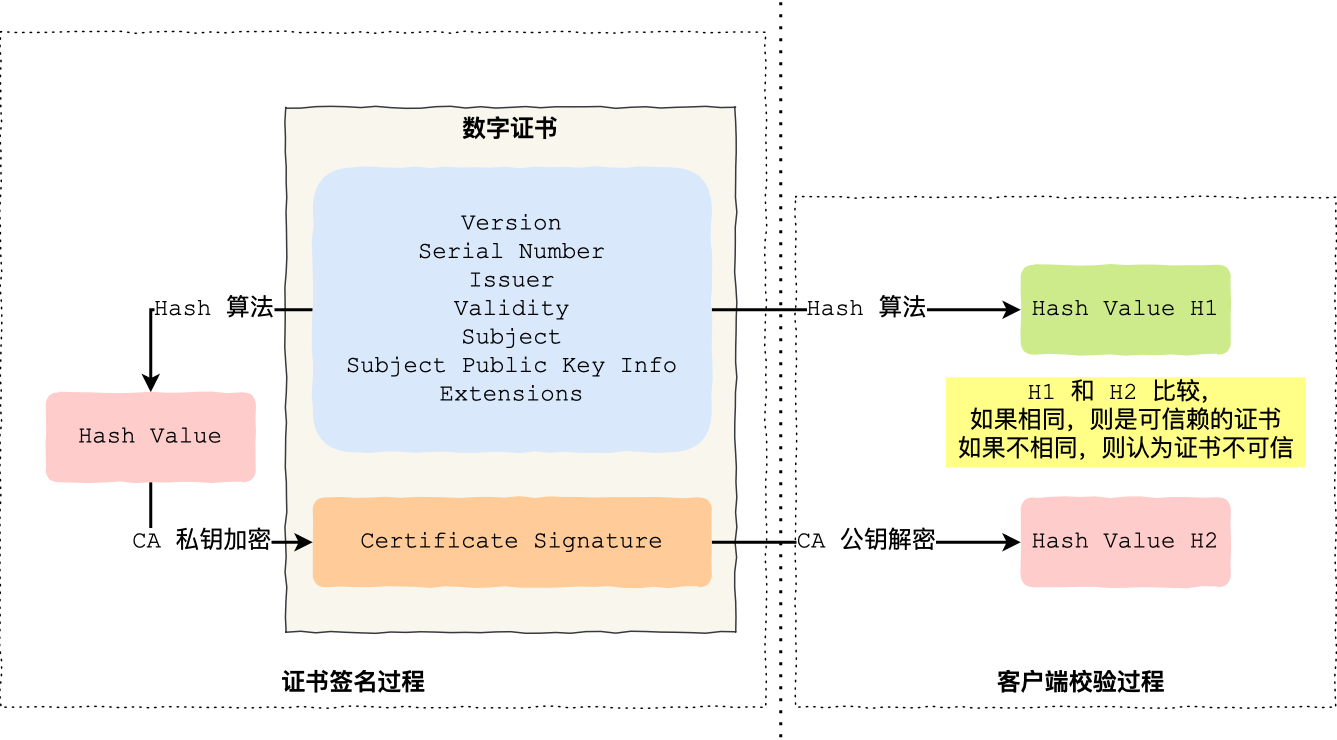
CA 签发证书的过程,如上图左边部分:
- 首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
- 然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
- 最后将 Certificate Signature 添加在文件证书上,形成数字证书;
客户端校验服务端的数字证书的过程,如上图右边部分:
- 首先客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
- 通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
- 最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
证书信任链问题:
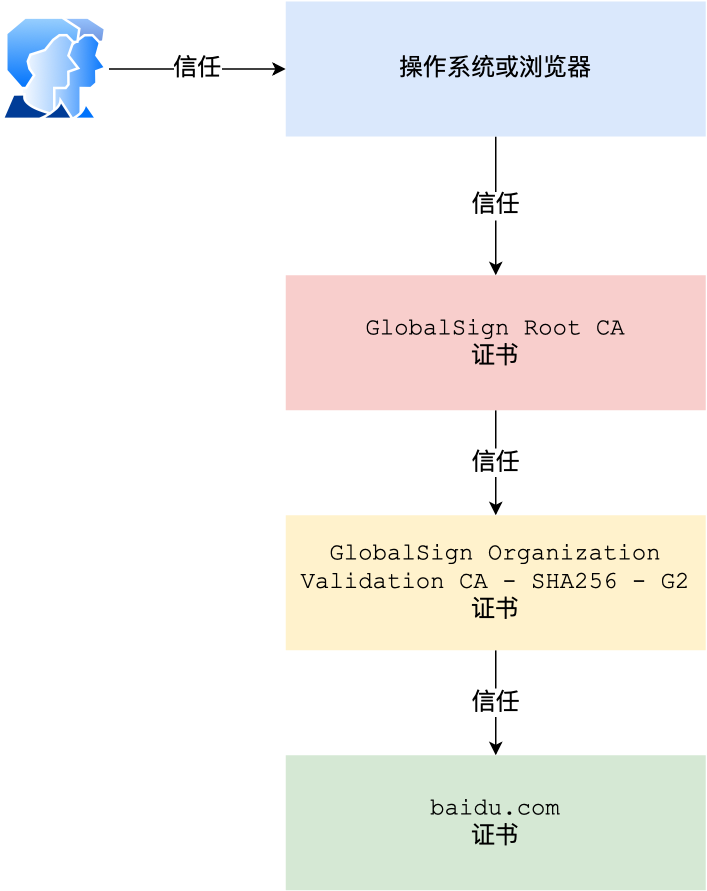
总括来说,由于用户信任 GlobalSign,所以由 GlobalSign 所担保的 baidu.com 可以被信任,另外由于用户信任操作系统或浏览器的软件商,所以由软件商预载了根证书的 GlobalSign 都可被信任。
为什么需要这么多层证书?为什么不直接都由root颁发?
这是为了安全问题,如果直接由root颁发,一旦root失守,整个CA机制都会瘫痪,边缘CA失守则不会那么严重
TLS记录协议
TLS 记录协议主要负责消息(HTTP 数据)的压缩,加密及数据的认证,过程如下图
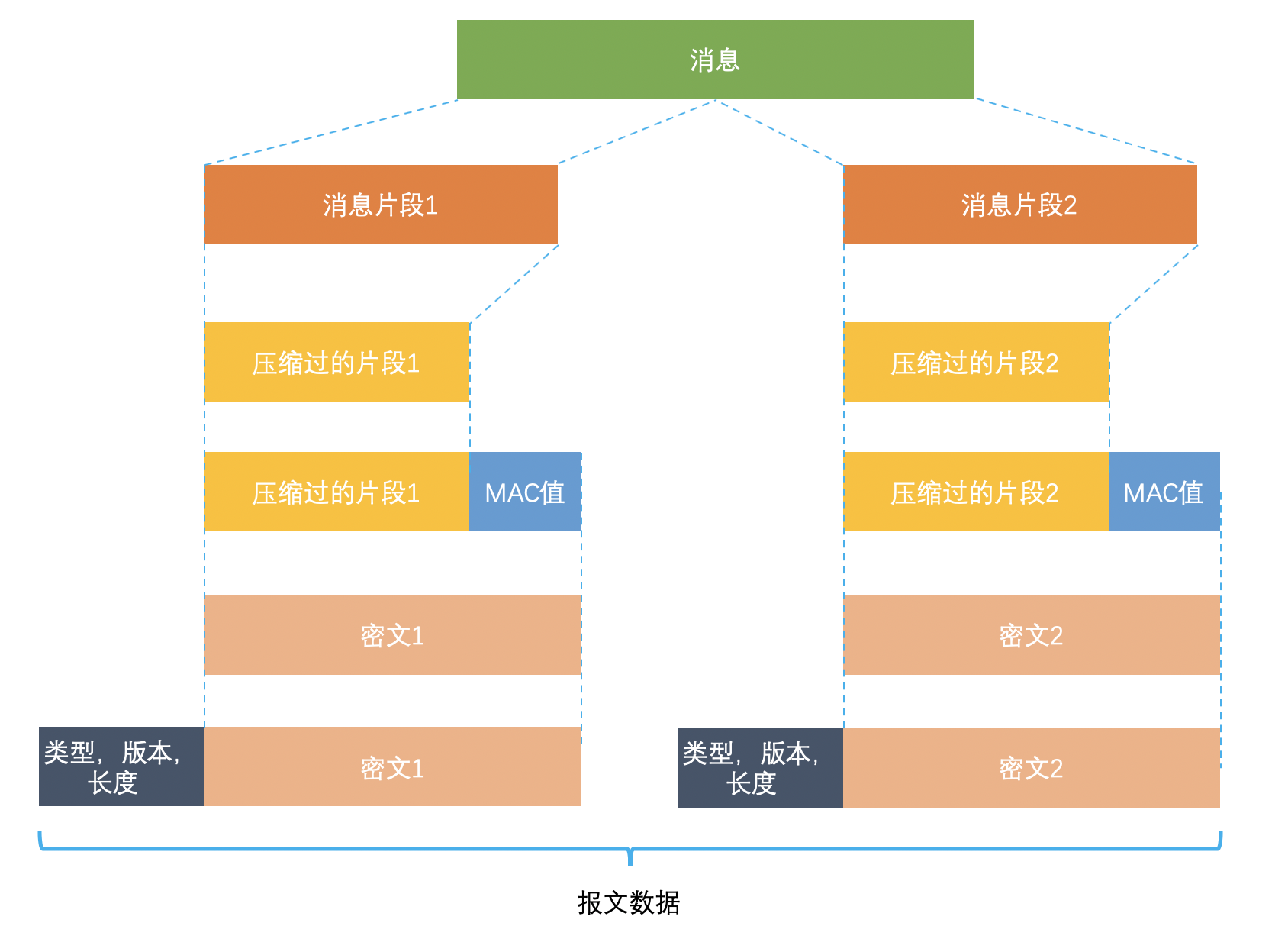
- 将消息分割为短片段,每个片段分别压缩
- 为每个压缩后的片段添加MAC值,可以通过MAC识别篡改和重放攻击(TLS记录维持了一个递增的序号,可以发现重传和重排,同时有一个不重数Nonce,可以防止重放整个TCP传输)
- 经过压缩的消息片段会和消息认证码一起通过对称密码进行加密
- 最后加上数据类型、版本、压缩后长度组成报头
HTTP/2的进步
- 头部压缩:一样或相似的头会被HTTP2干掉,通过一个HPACK算法,客户端和浏览器一起维护一张头部信息表,生成一个索引号,以后就不用发同样字段了,只发索引号
- 二进制格式,HTTP2的头和数据体都是二进制,并且统称为头信息帧和数据帧
- 并发传输:HTTP2可以复用一个TCP连接,每个TCP连接拥有多个Stream,Stream里面可以包含一个或多个Message,Message对应HTTP/1中的请求或响应,不同的HTTP请求用独一无二的Stream ID来区分,接受端可以通过Stream ID组装信息
- 服务器推送:服务端不再被动的响应,还可以主动地推送信息,客户端发出的Stream必须是奇数,服务器发出的stream必须是偶数
Http2的瓶颈:因为TCP协议
一旦丢包,就会触发TCP的重传机制,而后续的报文,即使已经缓存到了内核中,也只能等待丢失的包重传,因为TCP要求字节数据完整且连续
HTTP/3的进步
既然HTTP/2在TCP层性能有瓶颈,那就扔了TCP!用UDP!
但是传输又得是可靠的,于是使用了基于UDP的QUIC协议,实现类似TCP的可靠性传输
QUIC没有队头阻塞、连接建立更快、连接迁移
连接迁移:QUIC协议通过连接ID来标记通信的两个端点,客户端和服务器可以各自选择一组ID标记自己,这样即使网络发生变化,比如wifi换5G,只要上下文信息不变,就可以直接复用连接,不用像TCP那样还要重连,避免了卡顿
HTTP3普及速度非常缓慢,很多设备不知道什么是QUIC,会把它当做UDP,有的看到UDP包就直接丢
TCP协议
为什么需要TCP协议?TCP协议工作在那一层?
IP层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。TCP工作在传输层
数据库基础·SQLite·Room
MySQL有哪些数据类型
- 整数(Int,还有大中小)
- 浮点数(Float,Double,Decimal)
- 字符串(Char,Varchat,Text(不区分大小写),Blob(区分大小写),Binary,也有大中小)
- 日期(Date,Year…)
- Enum(映射到数字,最多65536,MySQL留了一个0来表示错误)(多个选项选一个,如果出错写空值)
- Set(最多64个项,多个选项选多个,如果有错,把错的扔了只留有效的)
数据库范式
1NF
现在的数据库写不出来的
2NF
所有的非主属性都要完全依赖于码
ABCD,如果AB是码,那么CD都应该由AB联合推出,而不是A或B单独就能推出
3NF,在2NF的基础上不允许传递依赖
ABCD,如果A$\Rightarrow$B,B$\Rightarrow$CD,就不行,(学号) → (所在学院) → (学院地点, 学院电话)
BCNF,2NF和3NF都只针对非主属性,BCNF进一步将限制推广到所有属性:且每个属性都不传递依赖于R的候选键
比如AB$\Rightarrow$D,BC$\Rightarrow$D,那么AB,BC都是码,从而ABC都是主属性,而这时如果A$\Rightarrow$C,就会让D有传递依赖,3NF是不会拒绝这种设计的,但是BCNF会拒绝
事务隔离级别
事务遵循ACID(要么不做,要么全做、事务执行前后,数据库都保持一致性状态、隔离性保证事务并发、事务结束后对数据库的修改是持久的)
- 读未提交:读了一个未提交事务修改过的数据,又叫脏读
- 不可重复读(Oracle默认的事务隔离级别):事务执行过程中如果多次读取数据,可能出现读到的结果不一样的情况,因为其他事务可能在事务处理过程中操纵了数据
- 可重复读(MySQL默认的事务隔离级别):事务多次读取得到的数据是一样的,但是仍然可能出现幻读
- 可串行化:事务可以被理解成一个个执行的,效率最低
幻读与不可重复度的区别
(1) 不可重复读是读取了其他事务更改的数据,针对update操作
解决:使用行级锁,锁定该行,事务A多次读取操作完成后才释放该锁,这个时候才允许其他事务更改刚才的数据。
(2) 幻读是读取了其他事务新增的数据,针对insert和delete操作
解决:使用表级锁,锁定整张表,事务A多次读取数据总量之后才释放该锁,这个时候才允许其他事务新增数据。
这时候再理解事务隔离级别就简单多了呢。
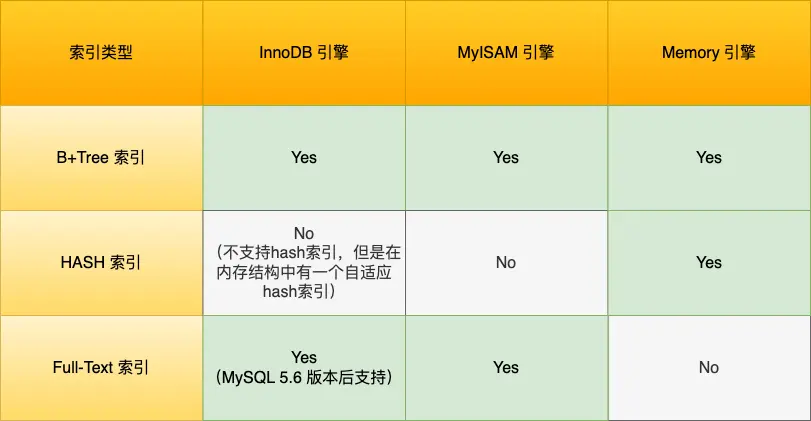
索引
按照数据结构分,有B+索引,Hash索引,Full-Text索引
设计模式与软件架构
设计模式原则
- 单一职责原则:一个类只应当有一个引起它发生变化的原因
- 开放封闭原则:一个实体应该对外扩展开放,对内修改关闭,即每次发生变化应当是添加代码,而不是修改代码
- 李氏替换原则:凡是父类出现的地方,子类应当都可以使用
- 依赖倒置原则:实现应当依赖于抽象,抽象不应当依赖于实现
- 接口隔离原则:一个接口不应当承担过多职责
- 合成复用原则:尽量采用聚合/组合,而不是继承,新的类可以委托已经实现的类来完成某些功能来实现复用
- 最少知识原则(迪米特法则):之和你最好的朋友通信,减少和其他人交互
MVC Model-View-Controller
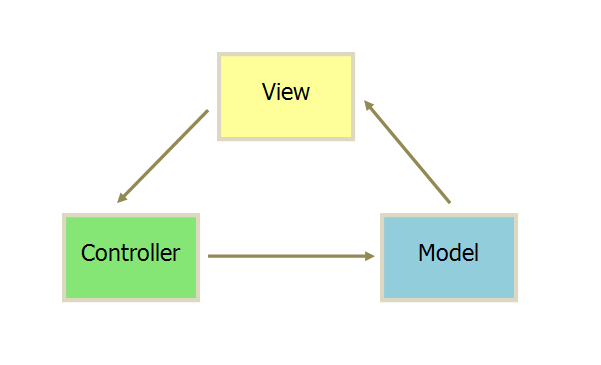
View传指令到Controller,Controller在业务逻辑完成后通知Model发生变更,Model变更后将数据发送到View,完成视图的更新
交互
用户与View交互,比如操纵DOM,View接受指令,并传递给controller
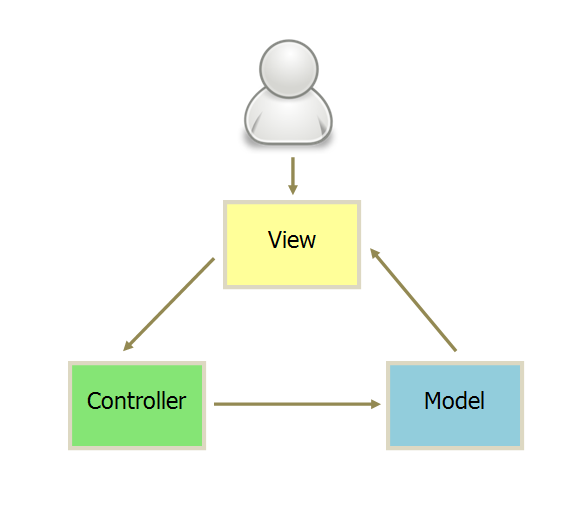
用户直接将指令给Controller,比如直接更改URL
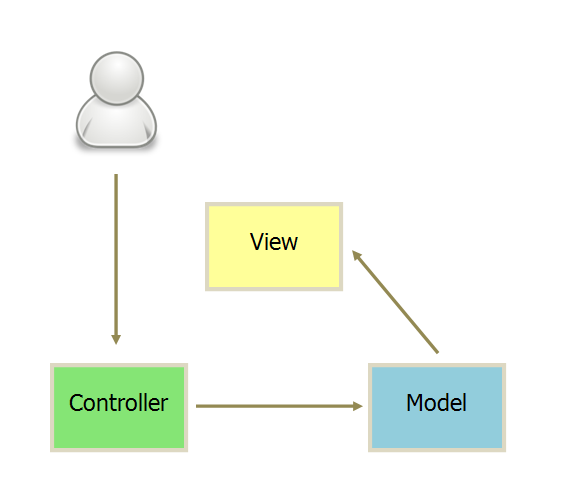
BackBone:MVC改进
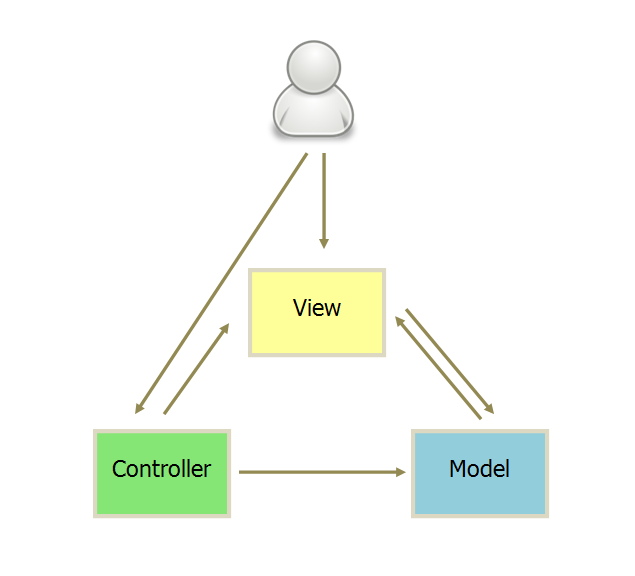
Controller几乎只保留的Router的作用,而View则变得很厚
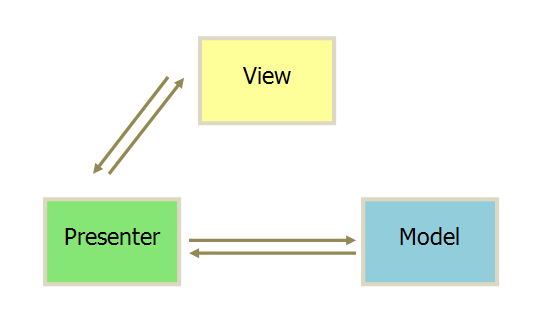
MVP Model-View-Presenter
将Controller改为Presenter,View不再与Model交互,而是改为Presenter与View双向交互,这种设计下View变得很薄,各种事情都交给Presenter来做
MVVM Model-View-ViewModel
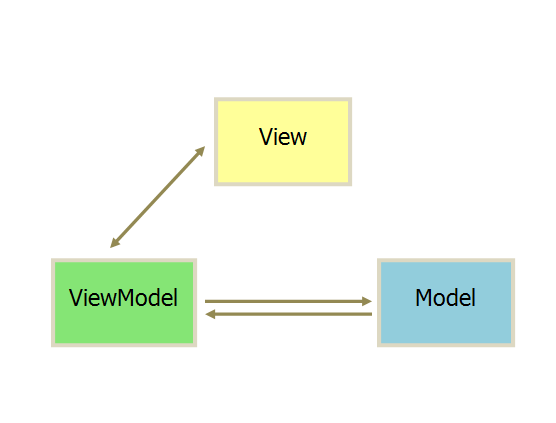
和MVP很像,但是将Presenter改为ViewModel,ViewModel和View之间采用双向绑定
Android中的MVVM
MVVM的本质是数据驱动,将解耦做得更加彻底
在Android中,Activity和Fragment扮演View的角色,ViewModel是VM,Repository类则集成Model的功能,提供对于外存、内存、网络数据的访问
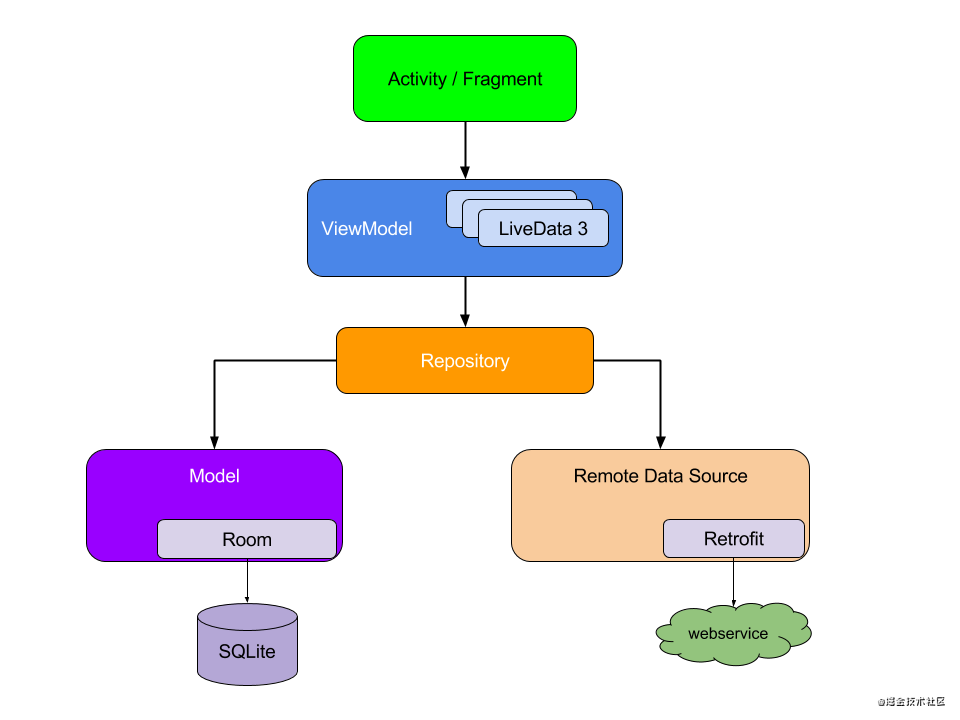
实现:
首先我们需要一个MyViewModel类继承自ViewModel
这个VM持有View需要的Data,它们被MutableLiveData(可以被更改的LiveData)包裹,同时VM应当开发接口让View获取这些MutableLiveData,但是注意提供的类型应当是LiveData,避免View直接将LiveData修改,不过有时候View就是需要修改Data,这时我们应该单独建立专门的Setter接口,而不是直接将MutableLiveData交给View,这将造成数据修改的不可控
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class UserListViewModel extends ViewModel {
//用户信息
private MutableLiveData<List<User>> userListLiveData;
//进条度的显示
private MutableLiveData<Boolean> loadingLiveData;
public UserListViewModel() {
userListLiveData = new MutableLiveData<>();
loadingLiveData = new MutableLiveData<>();
}
public LiveData<List<User>> getUserListLiveData() {
return userListLiveData;
}
public LiveData<Boolean> getLoadingLiveData() {
return loadingLiveData;
}
...
}在Activity中获取LiveData并通过Observe方法监听LiveData的更改,这样View和ViewModel就被绑定起来了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//UserListActivity.java
...
//观察ViewModel的数据,且此数据 是 View 直接需要的,不需要再做逻辑处理
private void observeLivaData() {
mUserListViewModel.getUserListLiveData().observe(this, new Observer<List<User>>() {
public void onChanged(List<User> users) {
if (users == null) {
Toast.makeText(UserListActivity.this, "获取user失败!", Toast.LENGTH_SHORT).show();
return;
}
//刷新列表
mUserAdapter.setNewInstance(users);
}
});
mUserListViewModel.getLoadingLiveData().observe(this, new Observer<Boolean>() {
public void onChanged(Boolean aBoolean) {
//显示/隐藏加载进度条
mProgressBar.setVisibility(aBoolean? View.VISIBLE:View.GONE);
}
});
}为了让App获取数据,我们单独创建一个Repository,这个类将代理所有数据获取过程,并开放简单一致的接口让ViewModel获取数据,这样ViewModel无需关系数据具体的获取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public class UserRepository {
private static UserRepository mUserRepository;
public static UserRepository getUserRepository(){
if (mUserRepository == null) {
mUserRepository = new UserRepository();
}
return mUserRepository;
}
//(假装)从服务端获取
public void getUsersFromServer(Callback<List<User>> callback){
new AsyncTask<Void, Void, List<User>>() {
protected void onPostExecute(List<User> users) {
callback.onSuccess(users);
//存本地数据库
saveUsersToLocal(users);
}
protected List<User> doInBackground(Void... voids) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//假装从服务端获取的
List<User> users = new ArrayList<>();
for (int i = 0; i < 20; i++) {
User user = new User("user"+i, i);
users.add(user);
}
return users;
}
}.execute();
}将ViewModel和Repository连接起来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42public class UserListViewModel extends ViewModel {
//用户信息
private MutableLiveData<List<User>> userListLiveData;
//进条度的显示
private MutableLiveData<Boolean> loadingLiveData;
public UserListViewModel() {
userListLiveData = new MutableLiveData<>();
loadingLiveData = new MutableLiveData<>();
}
/**
* 获取用户列表信息
* 假装网络请求 2s后 返回用户信息
*/
public void getUserInfo() {
loadingLiveData.setValue(true);
UserRepository.getUserRepository().getUsersFromServer(new Callback<List<User>>() {
public void onSuccess(List<User> users) {
loadingLiveData.setValue(false);
userListLiveData.setValue(users);
}
public void onFailed(String msg) {
loadingLiveData.setValue(false);
userListLiveData.setValue(null);
}
});
}
//返回LiveData类型
public LiveData<List<User>> getUserListLiveData() {
return userListLiveData;
}
public LiveData<Boolean> getLoadingLiveData() {
return loadingLiveData;
}
}在View中初始化时调用getData()方法,让ViewModel获取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32//UserListActivity.java
public class UserListActivity extends AppCompatActivity {
private UserListViewModel mUserListViewModel;
private ProgressBar mProgressBar;
private RecyclerView mRvUserList;
private UserAdapter mUserAdapter;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_user_list);
initView();
initViewModel();
getData();
observeLivaData();
}
private void initView() {...}
private void initViewModel() {
ViewModelProvider viewModelProvider = new ViewModelProvider(this);
mUserListViewModel = viewModelProvider.get(UserListViewModel.class);
}
/**
* 获取数据,调用ViewModel的方法获取
*/
private void getData() {
mUserListViewModel.getUserInfo();
}
private void observeLivaData() {...}更加高级的单向绑定与双向绑定(个人感觉更像语法糖)
单向绑定:
在Xml中添加这段
1
2
3
4
5<data>
<variable
name="user"
type="com.llw.mvvm.User" />
data>需要绑定的组件这样写
1
2
3
4
5
6
7
8
9
10
11<TextView
android:id="@+id/tv_account"
android:text="@{user.account}"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>
<TextView
android:id="@+id/tv_pwd"
android:text="@{user.pwd}"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>使用DataBindingUtil生成DataBinding类
1
ActivityMainBinding dataBing = DataBindingUtil.setContentView(this,R.layout....);
DataBinging会在编译时为我们生成对应组件快速访问的字段,就不用findViewById了
手动刷新数据,数据绑定的组件也会刷新
1
user.setPwd(dataBinding.etPwd.getText().toString().Trim());
双向绑定:
双向绑定将Xml中的data改成ViewModel
1
2
3
4
5<data>
<variable
name="viewModel"
type="com.llw.mvvm.viewmodels.MainViewModel" />
data>要绑定的组件
1
2
3
4
5
6
7
8
9
10
11
12<TextView
android:id="@+id/tv_account"
android:text="@{viewModel.user.account}"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>
<TextView
android:layout_marginBottom="24dp"
android:id="@+id/tv_pwd"
android:text="@{viewModel.user.pwd}"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>这种写法可以吧ViewModel里面的MutableLiveData数据一起改了
触发更新
1
user1.observe(this, user2 -> dataBinding.setViewModel(mainViewModel));