用户程序
系统级API
操作系统
指令集
硬件系统
高速缓存 Cache
原理
cache可以被分为set和line,一个cache有多个set,每个set里有多个line,每个line对应一个内存block
直接相联 Direct-mapped cache
可以看成每个set只有一个line的cache
每个内存块都注定要被映射到cache中一个确定的位置
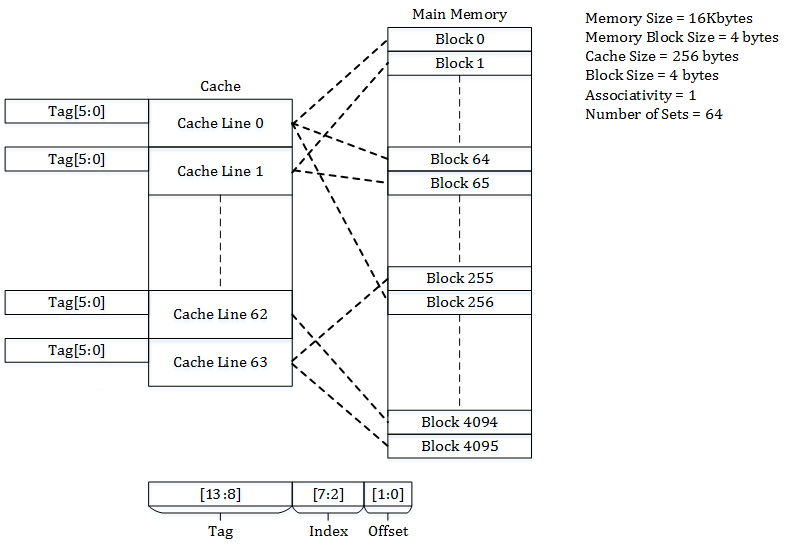
一个地址被分为了tag,index,offset三个部分,index就注定了这个字节会被分到哪一个cache line,但是有很多字节会被映射到同一个cache line,这个时候就可以通过tag来区分
优点:查找速度很快,cache对应的index行上的tag是就命中,不是就没命中
缺点:替换策略太直接,一些特定的代码可能连续疯狂替换cache反而导致速度变慢
全相联模型 Associative mapping
可以看成只有一个set,这个set包含所有line的cache
一个地址可能被分到任何一个line
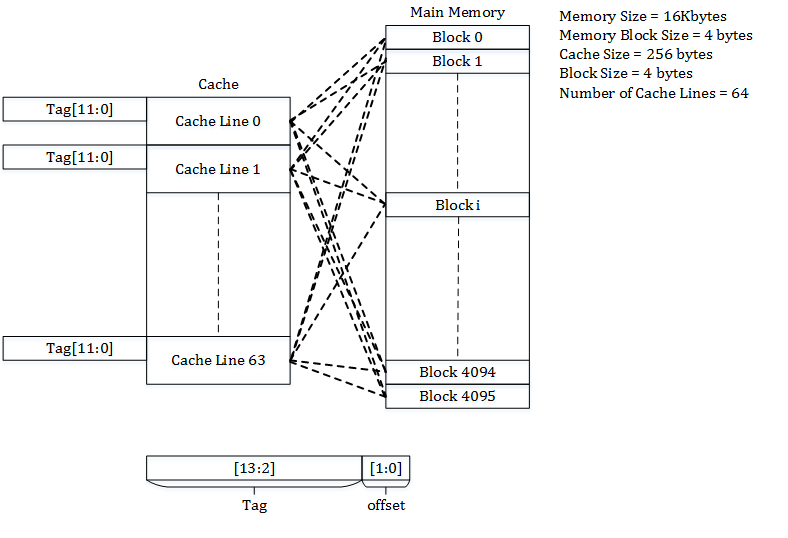
一个地址被分为tag和offset,要判断命不命中,就得整个cache搜一遍,挨个看tag是不是一样,如果cache塞满了要用一些算法替换,比如LRU
优点:往往能比较好的捕捉时空局部性
缺点:经常做全表搜索然后发现没命中,比较搞心态
组相连模型 Set Associative mapping
每个block都注定会映射到一个特定的set,但在set当中可以随机的放,如果一个set被塞满了,那么就根据一些策略替换某行
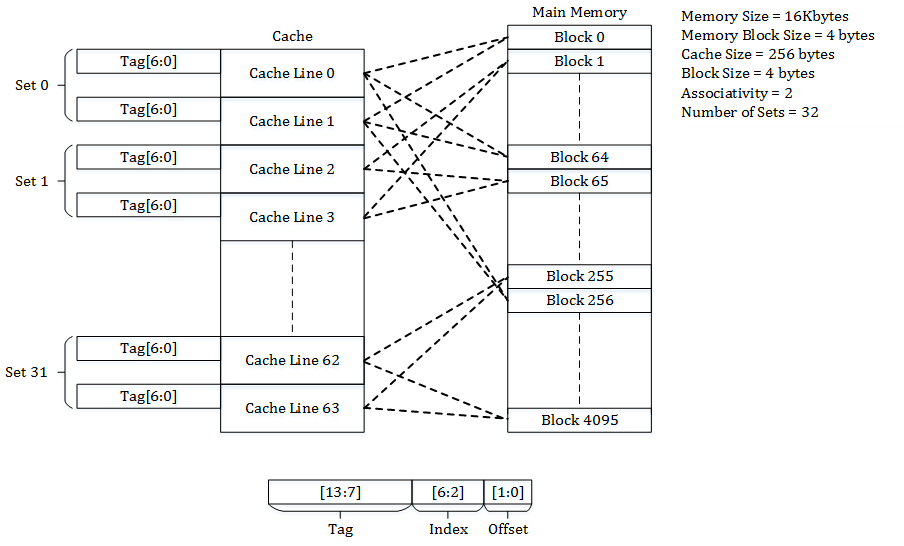
中庸之道,中和了二者的优点,也中和了缺点
倾斜相连cache Skewed-associative caches
这种cache 的设计利用了哈希散列,比如二路组关联的cache,它的每个组的第一line被用来注定映射内存,即每一个内存都能有自己注定要映射到的line,但是它的第二line,被交给的一个hash函数,hash函数对内存地址进行散列,这样如果一个内存地址注定的地方发生冲突,它可以不着急,而是再进行一次散列,看看能不能找着位置
这里得挖个坑以后来填了,cache,光是wiki上的内容就超级多了,现代架构cache、读写控制、多级控制、与TLB结合…
工艺模型
晶体管
Notion Collection
“如果哪天编译技术发展到程序员只要写串行程序, 计算机能够自动并行化并在成千上万个处理器中运行该程序,那这座桥的评分可以得 “特优”。”
并行化技术可能是一个研究方向
“RISC 指令系统的最本质特征是通过 load/store 结构简化了指令间关系,即所有运算指令都是对 寄存器运算,所有访存都通过专用的访存指令(load/store)进行。”
“页式虚拟存储管理将各进程的虚拟内存空间划分成若干长度相同的页,将虚拟地址和物理地 址的对应关系组织为页表,并通过硬件来实现快速的地址转换。现代通用处理器的存储管理单元 都基于页式虚拟管理,并通过 TLB 进行地址转换加速。”
个人认为,页式存储最大的意义在于向程序隐藏了它的内存地址空间七零八落和可能相当受限的事实,提供了看起来连续统一并且挺大的的虚拟空间,再在硬件级别进行真是地址的映射,至于虚拟内存,缺页中断,那又是请求分页机制所发明的技术了,不过相对于分段机制而言,分页机制主要通过统一大小并且比较小的页解决外部碎片
那为什么还要段页式存储呢?因为页表占用的空间太大了,单张页表也许看起来好,但是每个程序都要有自己的页表,就会产生巨量的空间消耗,同时分段可以提供一些共享和保护机制:
A big challenge with single level paging is that if the logical address space is large, then the page table may take up a lot of space in main memory. For instance, consider that logical address is 32 bit and each page is 4 KB, the number of pages will be 2^20 pages. The page table without additional bits will be of the size 20 bits * 220 or 2.5 MB. Since each process has its own page table, a lot of memory will be consumed when single level paging is used. For a system with 64-bit logical address even a page table of single process will not fit in main memory. For a process with a large logical address space, a lot of its page table entries are invalid as a lot of the logical address space goes unused.
我们可以将程序分成四个段,也就是我们一般常说的代码段,数据段,栈区,堆区:
这样我们既可以通过操作系统分配合适大小的段来控制程序分配到的内存,控制的页表的大小,同时还能利用段表的大小与偏移量的检查机制来避免各个区之间相互访问,达到保护程序的目的(比如实现可读可写则不可执行的保护限制)
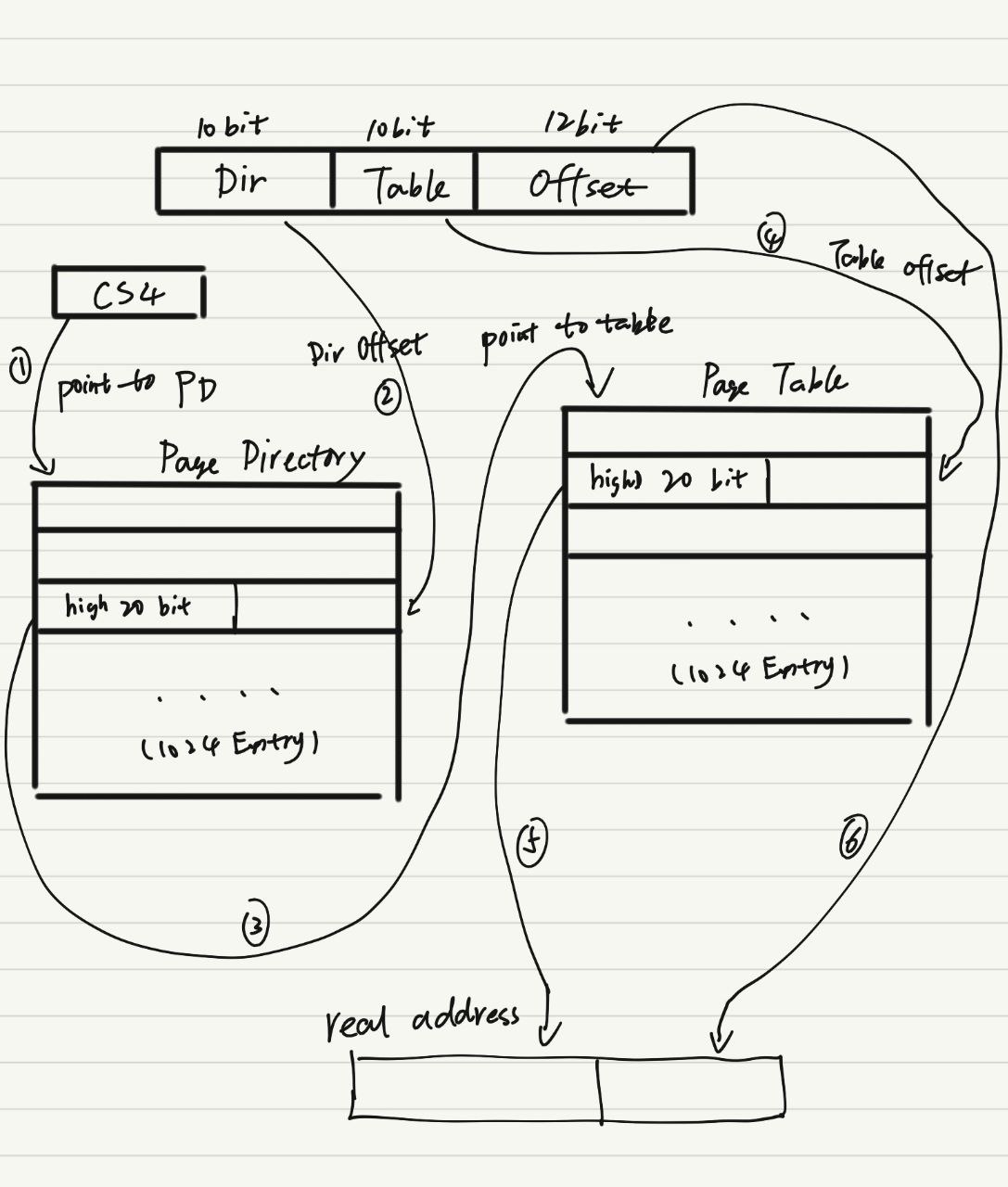
i386 采用二级页表结构,寻址如下图(图片没有体现权限控制的部分)