Week 1
| Process | Progress |
|---|---|
| Basic Knowledge | 了解高斯过程(Gaussian Process)与高斯过程回归 |
| Few-shot learning | Reading Literature Review Generalizing from a Few Examples: A Survey on Few-Shot Learning并阅读其中提到的一些论文 |
| Ideas | |
| Thesis Research | |
| Interest |
Gaussion Process Regression
Gaussion Process
- 协方差矩阵svd分解
Few-shot learning
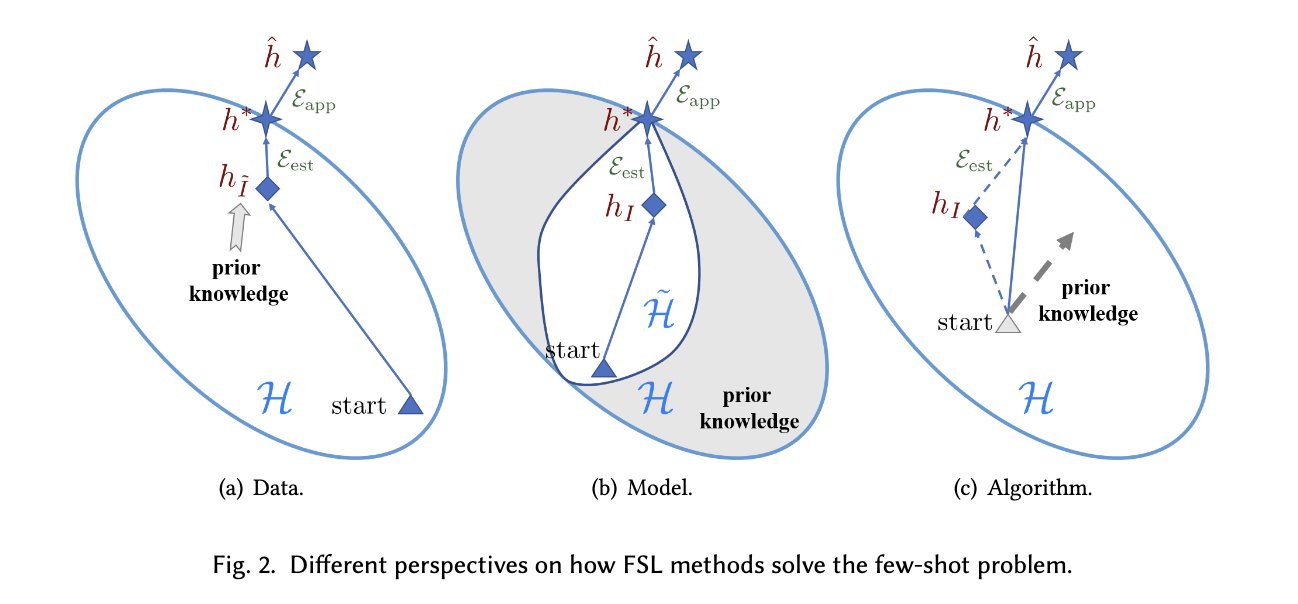
至少这篇综述的作者将few-shot learning的最大问题归结为“无法找到一个可靠的经验风险最小化”,并依据逼近最佳经验风险最小化的方法将few-shot learning的研究分为三大方向:通过利用先验知识丰富数据集的Data方向,通过提供更加精准的先验假设减小假设空间的Model方向,通过训练时使用更有针对性的算法逼近最佳假设的Algorithm方向
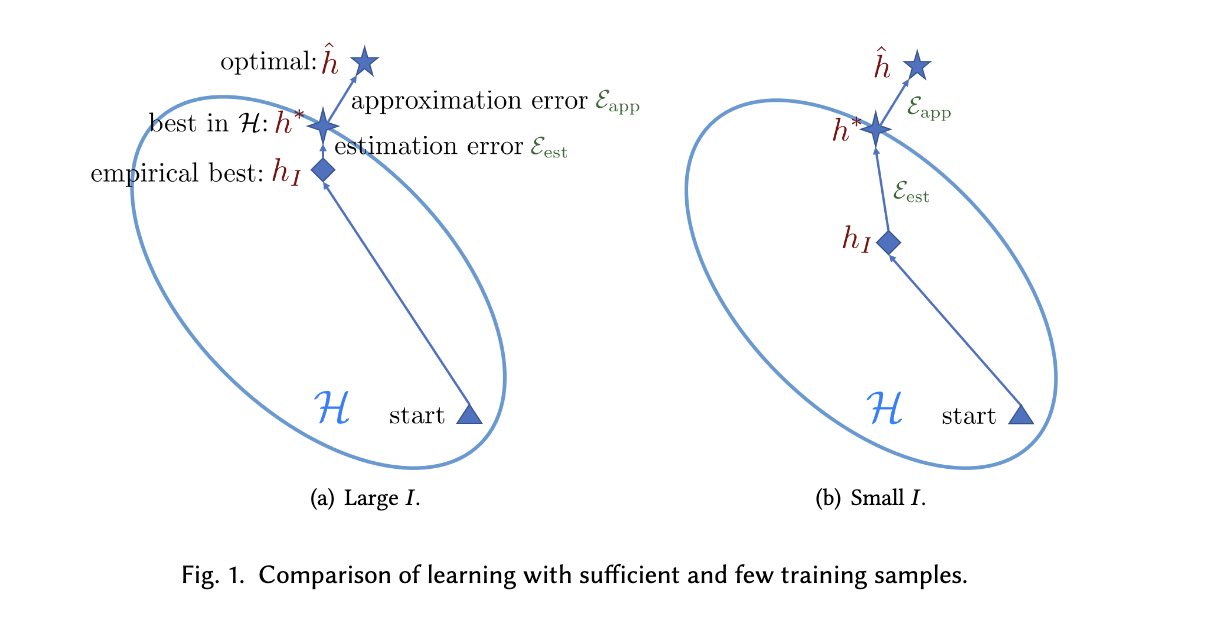
2.3.2 Unreliable Empirical Risk Minimizer. In general, Eest(H, I ) can be reduced by having a larger number of examples [17, 18, 41]. Thus, when there is sufficient training data with supervised information (i.e., I is large), the empirical risk minimizer hI can provide a good approximation R(hI ) to the best possible R(h∗) for h’s in H . However, in FSL, the number of available examples I is small. The empirical risk RI (h) may then be far from being a good approximation of the expected risk R(h), and the resultant empirical risk minimizer hI overfits. Indeed, this is the core issue of FSL supervised learning, i.e., the empirical risk minimizer hI is no longer reliable. Therefore, FSL is much harder. A comparison of learning with sufficient and few training samples is shown in Figure 1.
Data
Transforming Samples from
M. G. Miller, N. E. Matsakis, and P. A. Viola, “Learning from one example through shared densities on transforms,” in Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head Island, SC, USA: IEEE Comput. Soc, 2000, pp. 464–471. doi: 10.1109/CVPR.2000.855856.
通过在讲原训练集里千奇百怪的手写数字进行图像变换求各个类别中的最小熵来提高数据集的质量,最终提升了分类器的水平
@inproceedings{Kwitt16a,
author = {R.Kwitt and S.Hegenbart and M.~Niethammer},
title = {One-Shot Learning of Scene Locations via Feature Trajectory Transfer},
booktitle = {CVPR},
year = 2016}
描述了一个数据集不完全的场景:对于一片海滩,绝大多数都是风和日丽的照片,下雨天的图片很少,这会导致机器识别率降低,通过模型学习原有图片库上的特征,得到一个转换器
这篇文章的Methodology部分看不懂,
作者将xi定义为:
Each image Ii is assigned to one of C scene locations (categories) with label yi ∈ [C]† and represented by a D-dimensional feature vector xi ∈ X ⊂ RD.
我认为xi是表示第i张图片的D维矩阵,同时作者提到每个图片还有一个人工标注的“瞬态属性”向量,大抵是反应这张图片收到大雾、风雨、黑夜等情况干扰的严重程度?
Additionally, each image is annotated with a vector of transient attribute strengths ai ∈RA+, where AT denotes the set of attributes and A = |AT |.
作者表示他们使用高斯过程回归模型来预测,
For a given scene location, we wish to estimate the path γk : R+ → X for every attribute in AT . In our case, we rely on a simple linear model to represent this path. Formally, lets fix the scene location c and let Sc = {i : yi = c} be the index set of the M = |Sc| images from this location. The model, for the k-th attribute, can then be written as
xi = wk · ai[k] + bk + ǫk
我这里不是很明白这个式子是通过ai合成xi,还是在用xi,ai求wk,qk?我感觉更像是后种


Week 2
| Process | Progress |
|---|---|
| Basic Knowledge | 学习基本的图像处理,包括霍夫变换,灰度矩阵,Rasterization 光栅化等 |
| Few-shot learning | Reading Literature Review Generalizing from a Few Examples: A Survey on Few-Shot Learning并阅读其中提到的一些论文 |
| Ideas | |
| Thesis Research | SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes(cvpr 2024) |
| Interest |
Thesis Research
LAA-Net: Localized Artifact Attention Network for High-Quality Deepfakes Detection (cvpr 2024 source code haven’t been uploaded)
一开始我以为这个方法能够甄别大模型生成的图片,但是看了文章所举的例子好像只能检测一张原图哪里可能被ps过,就失去了兴趣
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes(cvpr 2024)
3D Gaussian Splatting for Real-Time Radiance Field Rendering (cvpr 2023 best-paper award)
最近关于Gaussian Splatting的文章似乎比较多,我个人有点感兴趣
图形学中的基本变换
MVP变换
Rasterazation 光栅化
算法流程
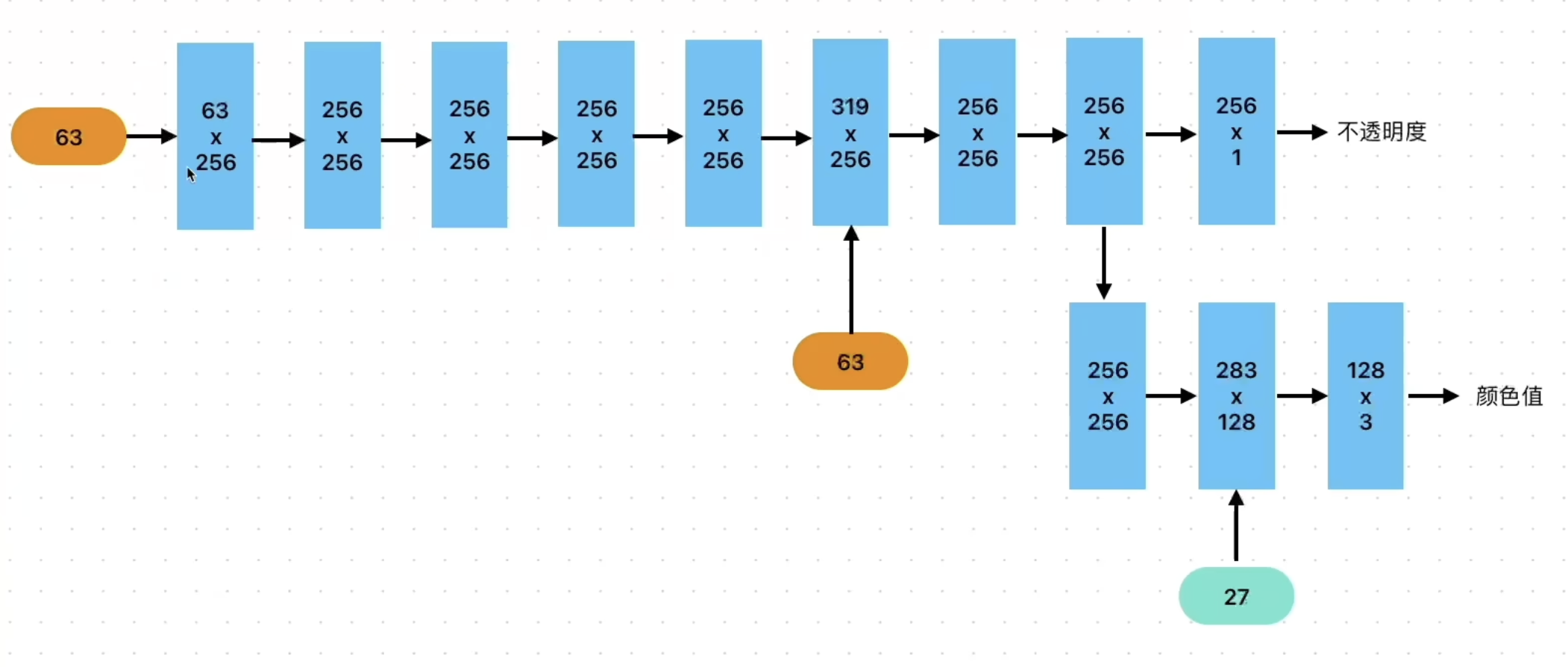
输入:一组静态图像和通过sfm分析后生成的有关图像的稀疏点阵
由于得到的点阵十分稀疏,所以很难估计法线,因此作者选择了不需要法线的3d gaussians

这个3d状态下的Gussian可以看做一个3d椭球,因此作者采用不是立方体或者锥体的表示形式,而是采用了椭球
椭球需要颜色和透明度信息,这里采用了球谐函数拟合颜色信息
这些椭球会被投影到二维平面,进行光栅化
Week 3
| Process | Progress |
|---|---|
| Basic Knowledge | |
| Few-shot learning | |
| Ideas | |
| Thesis Research | SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes(cvpr 2024) 3D Gaussian Splatting for Real-Time Radiance Field Rendering |
| Interest |
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Naive Thoughts
- 能否使用更加复杂的网络达到更好的效果?Resnet?
- 能够使用更加复杂的溅射模型表示更细粒度的3d信息?球谐函数溅射?
- 能否使用类似corpas的手段减少模型预测需要的图片样本?
- Large model for filling the blank space? (Someone already started, see: dreamgaussian)
- Gaussian模型渲染的结果太大了,可能难以用于游戏、网页等场景(个人猜测),如何通过一些手段在不怎么降低精度的同时减小大小,比如移除不必要的渲染,尝试用更少的guassian,用更复杂的模型进行溅射,平滑化?
Method
使用Gaussian模型表示世界
Our representation has similarities to previous methods that use 2D points [Kopanas et al. 2021; Yifan et al. 2019] and assume each point is a small planar circle with a normal.
作者借鉴2021年发表的一篇文章,这篇文章将每一个点都看做具有法线的小平面圆,但是做法对于极度稀疏的sfm点集不合适,因为预测和优化它们的法线过于困难(我还没详细了解为什么困难),所以作者最后采用了不要法线的几何模型:
3维高斯
可微渲染 Differentiable rendering: 重要性与难点,以及为什么3维高斯是一个很棒的可微渲染基础
不论是通过图片获得3d模型,还是通过3d模型渲染2d图像,引入深度神经网络都是十分诱人的,但是要引入神经网络,以3d模型渲染2d图像来说,需要保证能找到这样一个渲染:
其中
如果R是一个函数Loss,我们就通过一个可微的损失函数,通过
进行反向传播和梯度下降操作,从而将这个渲染过程加入到神经网络中
3维高斯、基于点的渲染与可微渲染
目前最流行(至少作者这么说)的渲染方式是基于点渲染 「其他的方式还有votex-based(基于体积的),Mesh-based(基于网的)我还没有详细了解这些方法」,输入是点云,输出是渲染的结果
但是基于点的方法最严重的缺陷在于它是严格不连续的,因此想进行可微渲染就十分麻烦,于是就出现了所谓的溅射“splatting”,它是指不再用一个“点”(不知道最原始的点云里面的点有没有大小?)而是用大于一个像素点的基元来代替点,比如圆、椭圆(上面作者引用的Kopanas的论文就采用了使用法线来表示方向的椭圆)、椭球(作者的3D Guassian模型渲染出来就像个椭球)等来表示(我还没想明白为啥溅射能解决点云严格不连续的问题,我能理解这个基元是可微的,但是基元和基元之间怎么办,难道是连续的吗?)
Example:NeRF——基于体渲染公式将MLP引入三维重建
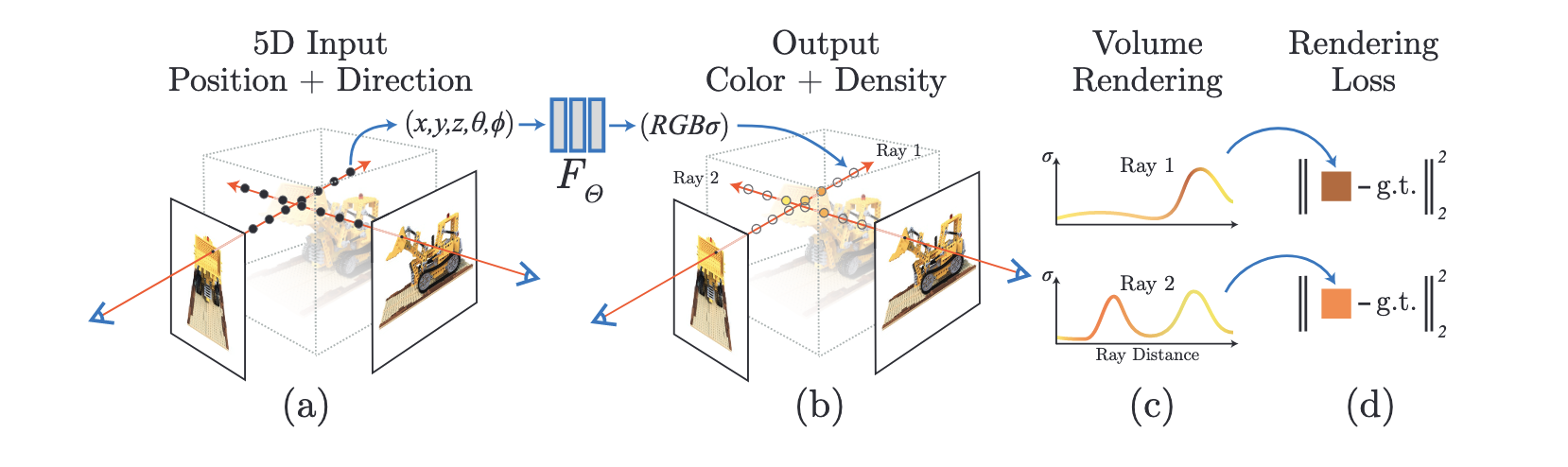
模型输入:
一个五维向量:前三维代表世界坐标系下点的坐标,后两维代表球坐标系表示的点的观察角度(代码中实际并不是这样,首先为了刺激模型,作者还引入了由sin和cos函数计算的高维数据,同时观察角度使用的也不是球坐标系)

NeRF采用的并不是基于点的渲染,而是基于体积的渲染,采用公式:

这个公式表示对于射线
从
其中,kerras.layer.Dense
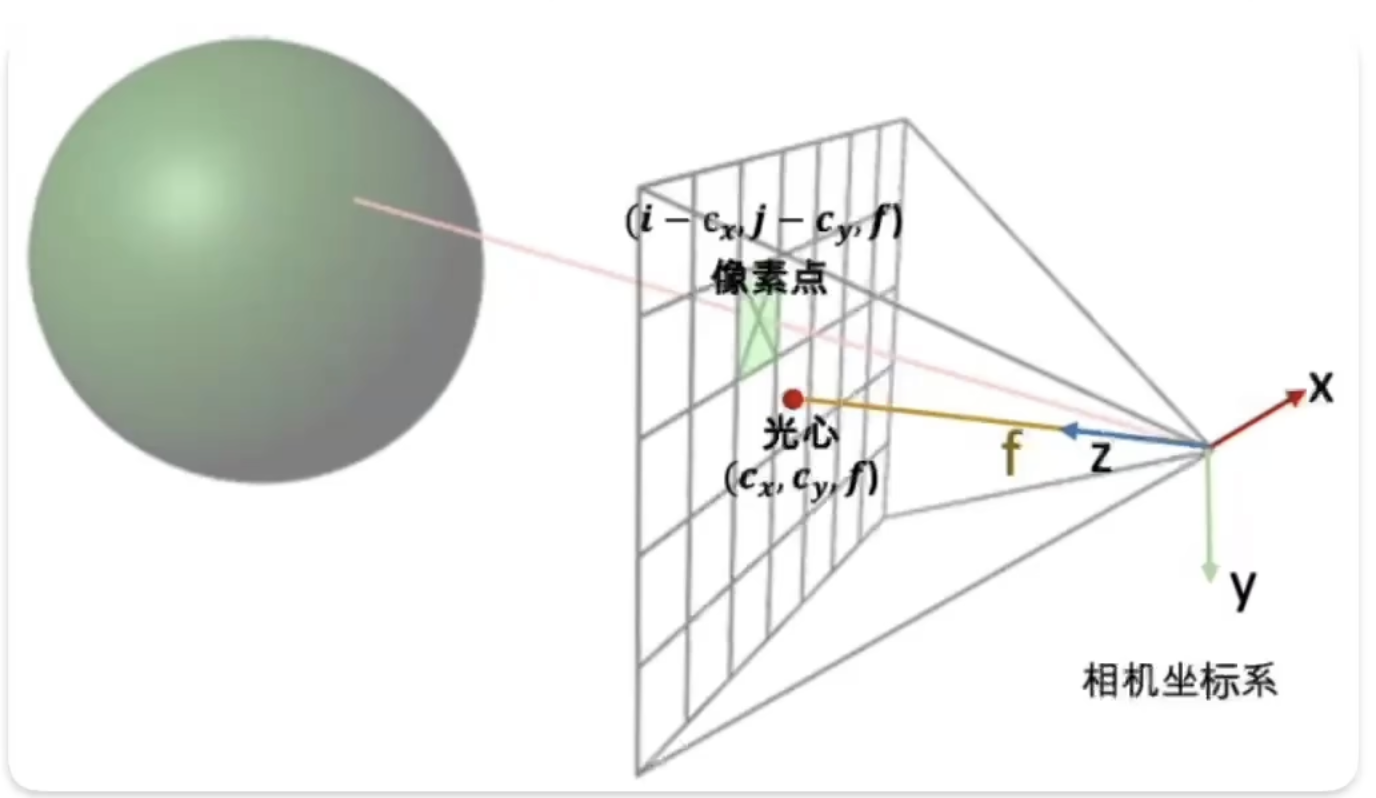
射线
1 | def get_rays(H, W, focal, c2w): |
为了让神经网络获得高频信号,NeRF作者发明了Position Encoding,通过一组sin cos函数将低频输入转换为高频信号(这个思想内核我还没有理解清楚)
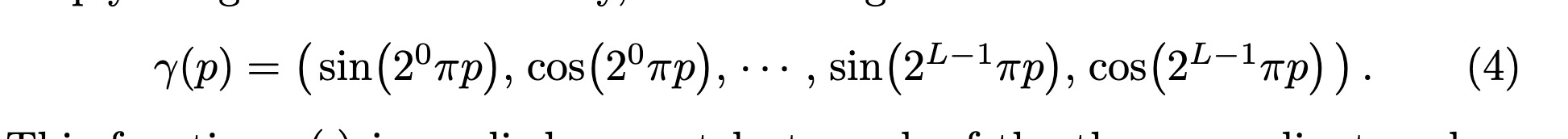
1 | def init_nerf_model(D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False): |
具体的训练过程:
stateDiagram-v2
相片像素 --> 相机坐标+视角
相机坐标+视角 --> 世界坐标+视角
世界坐标+视角 --> 输入mlp网络
输入mlp网络 --> 预测空间密度与颜色
预测空间密度与颜色 --> 使用体渲染公式得到图像
使用体渲染公式得到图像 --> 与测试图像比较获得loss
与测试图像比较获得loss --> 根据loss进行反向传播
Gaussian Splatting
sfm提供的点被初始化,提供一些Gaussian椭球,然后对高斯椭球对特定的方向进行投影得到2D高斯分布(看起来就像一个个椭圆),对这些椭圆进行光栅化,得到2d图像,使用距离和D-SSIM构造一个损失,通过反向传播进行优化,这里的Adaptive Density Control 用于进一步改善3d Gaussian的分布。
对高斯椭球进行投影
作者基本参考这篇文章:EWA volume splatting
首先一个中心为

最后可以得出这个公式(我还没细看数学原理):

其中W对
Back probackation
同时为了更好的适配梯度下降,作者没有采用协方差矩阵的标准定义(因为协方差矩阵必须是半正定的,而半正定矩阵这个条件很容易被梯度下降过程破坏),最后作者还是采用了更像椭球溅射的表示,用一个缩放矩阵


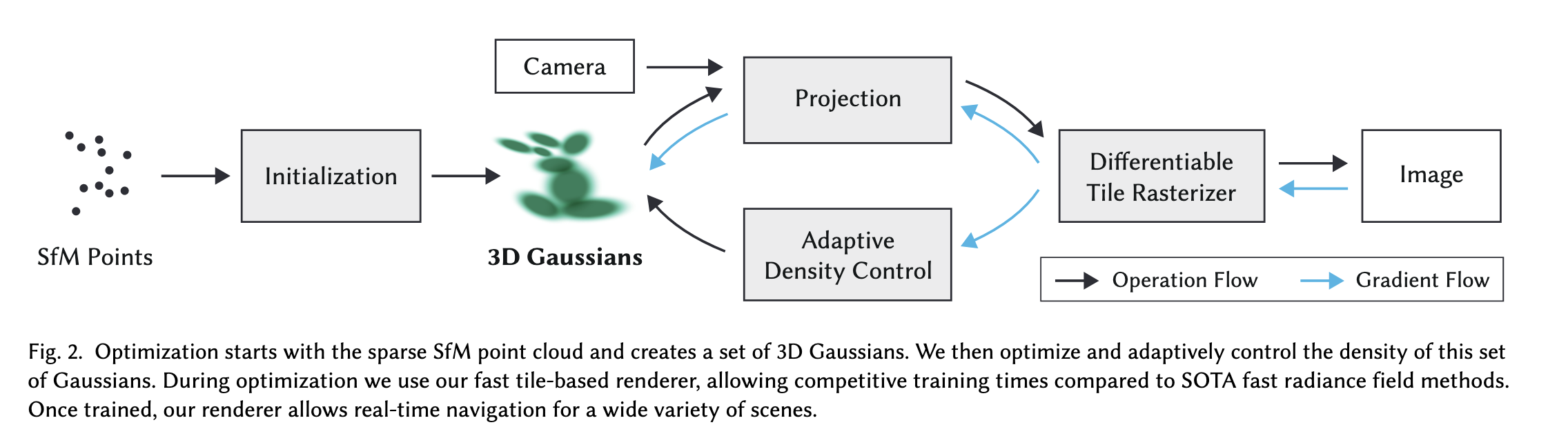
Adaptive Density Control
反向传播可以更新高斯椭球的形状、大小、透明度和颜色,但是高斯椭球的数量、位置等信息无法直接通过反向传播更新,作者额外构建了Adaptive Density Control 机制实现对这些信息的更新
对高斯椭球的移除实现上每100轮做一次,遍历所有的高斯椭球,移除那些
对于添加,反向传播的参数能看出一些端倪,比如一个高斯椭球有关位置
同时一些地方可能存在一个奇大无比的高斯椭球并且出现了过拟合的情况,这时就要在该区域添加高斯椭球,作者采用的方式时将原本的高斯椭球通过一个超参数变小,然后克隆两份

高速光栅化(超越NeRf的关键)Fast Differentiable Rasterizer for Gaussians
关键:Tile based, Pre sort Gaussian
NeRF需要对每一个像素构建一个射线,每一个射线进行一大堆采样
总体来说,经典的点云可微渲染是这样的:


tile based rendering 基于图块的渲染
作者将整个屏幕空间分成了16
然后根据每个高斯球体覆盖的tiles实例化它们,同时用一个类似hashtable的结构进行存储,键值记录了空间深度和tile ID
接下来根据键值对guassian椭球进行排序,排序算法使用Radix sort,这种排序算法可以利用GPU进行高速排序
GPU Radix sort


只需要完成这一次排序,后续的渲染都可以依据此进行
完成排序后,对于每个tile都可以构建一个list,记录针对该tile从前往后的guassian list
开始渲染,首先对于每个tile启动一个线程池,将前面构建的高斯椭球表加载到共享内存中,然后针对每一个像素(我在想这里能不能并行?)从前往后遍历每个tile的list,当
这个高速渲染的过程不仅加速了渲染,也加速了反向传播的过程(还没细看)
Week 5
| Task | Progress |
|---|---|
| Learning the Basics for Gussian Splatting and Generation Models | learning Basic VAE, GANs |
| 3D gaussian splatting reconstructions for Human Body | |
| Other interesting works for 3D gaussian | DreamGaussian |
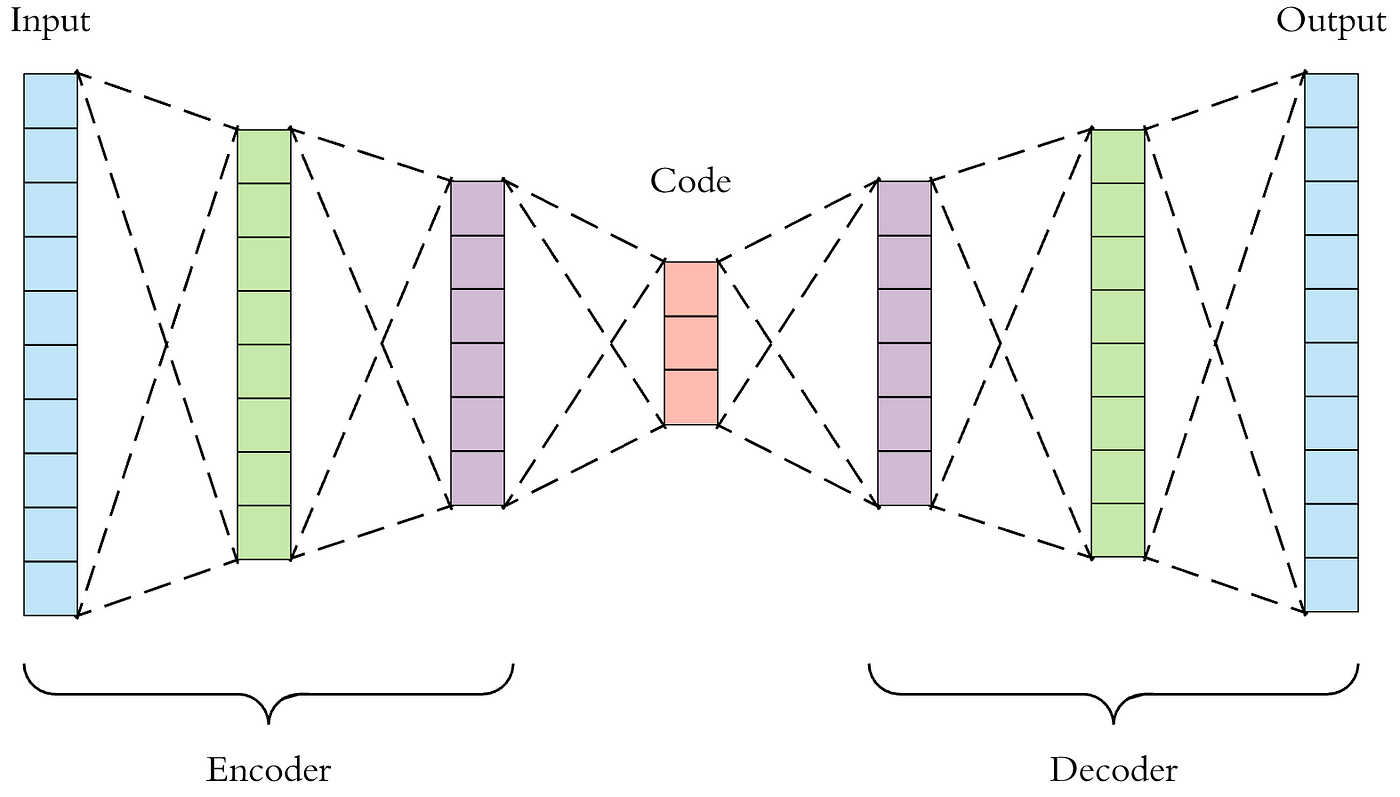
VAE
autoencoder
最原始的想法是通过Encoder寻找一个将原始图像压缩后的latent,并且确保可以通过一个decoder从这个latent生成相同类型的图像
variational autoencoder
但是仅仅得到一个固定的向量latent十分无聊,因为这个latent并不能很好的反应input x之间的关系,例如两个类似的图像,它们得到的latent可能完全不一样,也不能对它进行特征合成之类的操作
variational autoencoder得到的并不是一个直接的latent,而是由参数
(我想这里我还得更加深入的看看,目前只是简单听了下UC Berkeley CS 198-126,还没看论文)
vector Quantised-variational autoencoder
基于高斯分布latent的vae,Encoder输出的是一个参数化的分布,但是对于一些任务,离散的latent会更加合适(比如NLP方向,不过我还没细想为啥是latent,我能想象到decoder的output应该是离散化的,因为词语没法连续,但是为什么latent也要是离散的?)
vq-vae采用了codebook和聚类的想法,将Encoder输出的那些非法的,不在codebook中的向量通过近邻算法聚类到相应的codebook中的类别去
(codebook中的类别要如何安排、损失和反向传播要如何进行这些问题还没有研究)
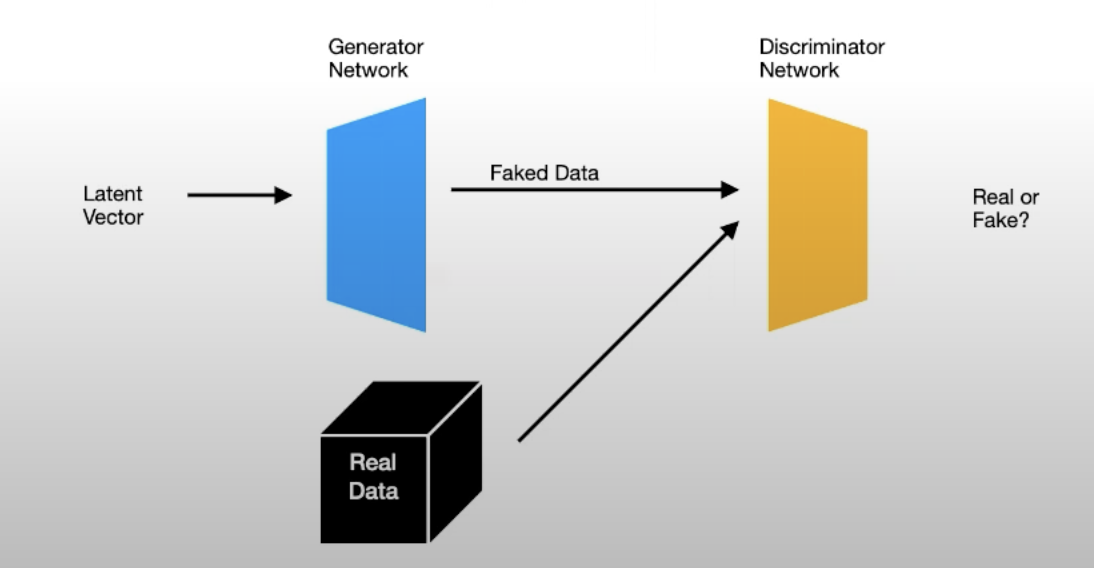
GAN
Arch
Cross Entropy
熵是用真实分布和真实编码计算平均编码长度,交叉熵是用真实分布(我们需要在具体任务中自行定义什么是真实分布)和预测编码计算平均编码长度
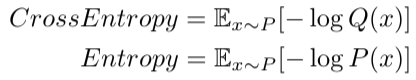
交叉熵与熵的差被叫做KL散度,我们可以利用
从而证明交叉熵始终大于等于熵(相等条件:预测分布等于真实分布),基于此可以构造各种各样的损失函数
Gan所采用的损失函数就是交叉熵(的负数),其中生成模型G尝试将这个损失最小化(负数绝对值越大,意味着D模型分类得越糟糕),而D模型则不断尝试将这个损失最大化

Conditional Gan
有时候我们可能有更高的生成要求,比如生成特定的数字或者特定的汉字,如果我们只是把一大堆数字图片和标签丢给Generator让Generator学习,而Discriminator又只能拿到图片的话,最后Generator可能会把9学习成6,而Discriminator没有办法阻止这一点
于是我们进一步改进,让Discriminator也能拿到标签,这样当D看到一个G生成的一个非常真是的6但是却打上了9的标签时能够及时识别为fake,这样G就不得不认真的分类学习了
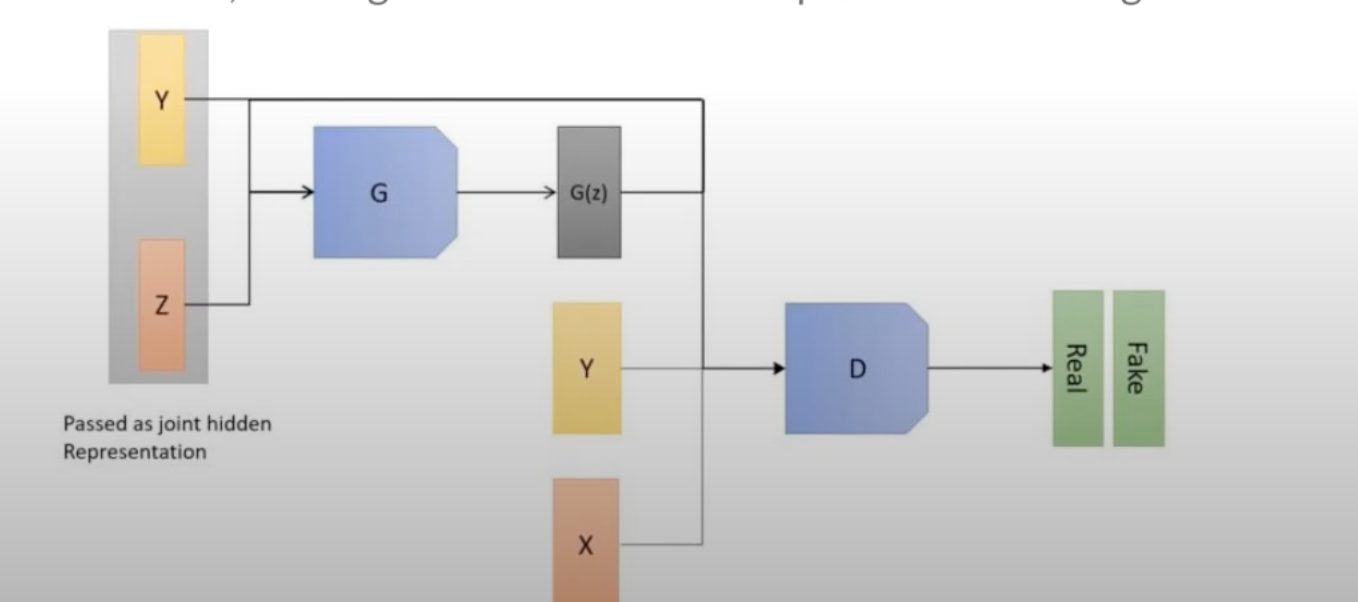
Gan 问题
- 如果D模型太强,交叉熵接近0,权重在反向传播时也接近0,G模型不知道怎么调整自己来继续和D模型比赛,直接摆烂睡大觉
- mode collapse,G发现有一张图片特别能迷惑D,于是为了取胜,G之后越来越倾向于输出这张图片,最后甚至只输出这张图片
- 损失不收敛,模型D和模型G会不断的竞争,损失也可能不断的摇摆,无法确定什么时候两个模型已经足够好,并且两个模型都有过拟合的风险
Improving GANs
我们可以稍微调整损失函数为

这样的损失函数在D模型完全判断正确时给出一个超大的loss,拍着G的屁股让它大踏步的改生成策略
Week 6
| Papper | Core Idea |
|---|---|
| HUGS: Human Gaussian Splats | 使用SMPL模型进行初始化,在训练中的高斯球云可以偏离这个初始化以便于适应衣服、头发等内容,使用三个MLP神经网络分别预测高斯椭球的future triplane中的颜色、透明度、缩放、旋转和LBS权重,从而对人体不同的动作和视角进行合成 |
| Gaussian Shell Maps for Efficient 3D Human Generation | 同样采用了SMPL进行初始化,不同的是采用了Multi Shell技术,将人体理解为一层一层向外包裹的Shell,同时通过GANS网络训练一层一层shell,使其与真是图像越来越接近,这种设计可以灵活的更换不同的shell层,从而实现给人体更换发型、服装等特性 |
HUGS: Human Gaussian Splats
HUGS将人体和环境都基于高斯球云进行表示,并使用SMPL模型初始化人体的高斯球云,为了更好的拟合SMPL模型中没有的头发、服饰等特征,高斯球云可以在后续训练中适当偏离SMPL模型。同时高斯椭球的颜色、不透明度、缩放、旋转、Linear Blend Skinning 权重等特征通过feature triplane(三平面特征)进行表征,通过训练三个MLP模型对feature triplane进行预测,并将预测得到的颜色球谐函数、缩放等属性用于构建人体,LBS权重则用于驱使高斯球云组成不同的人体形态,从而实现新动作的合成。
Gaussian Shell Maps for Efficient 3D Human Generation
GSM结合了3D 高斯和基于CNN的生成式网络,核心思想是将3D高斯锚定到一系列基于SMPL模型生成的壳(Shell)中,并通过生成模型生成对应的shell map,并作为对应Gaussian的颜色、透明度等特征的来源,同时引入GANs网络对渲染结果进行优化,并针对人体专门提供了甄别手足、面部的Discriminator。通过将高斯球体与shell基于重心坐标一一锚定,变化高斯球云可以通过首先变换Shell mesh,再查询高斯球体在变换后的shell mesh中对应的顶点来获取变换后的位置。
GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
GauHuman同样基于SMPL模型进行初始化,并且同样引入MLP模型对LBS权重进行预测,与HUGS不同的是,GauHuman并没有使用feature triplane来表示高斯球体的颜色、缩放等特征,(这句我不能确定)而是仍然将这些信息存储直接在高斯球体中,这进一步提高了渲染效率,同时为了避免直接使用MLP模型预测LBS权重带来的时间开销和低质量的渲染效果,GauHuman引入两个针对SMPL LBS权重进行细化的MLP模型,其中
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
GaussianAvatar同样使用了SMPL模型进行初始化,对于输入的单目视频中特定的一帧所对应的SMPL模型,GaussianAvatar首先对该SMPL模型采样得到一个UV positional map I,并传递给一个pose encoder以得到一个Pose Feture,由于单目视频带来的数据偏差,仅仅通过这个Pose Feature进行训练很容易导致模型对某些常见帧的过拟合,GaussianAvatar还引入了一个Optimizable Feature Tensor来学习粗略的动作表征以增强泛化性,二者整合后,由一个训练好的AutoDecoder解码获取高斯球体颜色、缩放等性质,最后将SMPL模型的LBS权重应用到人体模型中,实现动作变换。
Week 7
框架 (技术分类,应用分类)
领域意义(Gaussian) 现有工作分类 每类展开 每类文章的特点,参考已有综述
略读,感兴趣的可以精读
综述应当压缩
输入输出,解决的问题,功能;现有方法的问题;怎么做的
摘要(任务),Introduction(现在的问题),Method(实现),(实验部分略过),related work(可以略过),appendix(一般是推导和补充)
这周被软工III的大作业压得喘不过气,主要是之前水得太狠了,只能邻近ddl的时候一通胡赶,所以这周的进展很小…
3DGS目前主要的应用分类
Simultaneous Localization and Mapping (SLAM)
主要是帮助快速建立一个当前环境的模型表示,对于智能机器人、自动驾驶设备有非常重要的作用
3dgs作为一个新的3d表示形式,其各向异性可以更好的描述场景,通过改进Adaptive density control,有机会实现对于现实环境实现更好的映射,同时3d高斯的计算加速也有助于更高效的场景建立
Dynamic Scene Modeling
动态场景建模,反映到我目前在看的人体主要有两个方面,一个是3D人体的重建及对于固定动作的动画化,另一个则是合成能做出全新动作的人体,后者比前者要求更高的泛化性。
AI-Generated Content (AIGC)
3dgs为***to 3d提供了新的3d场景表示,相较于NeRF的隐式表示,3D高斯显式的表示场景,更适合作为生成模型的生成目标,同时3dgs作为场景表示也更由于过去基于DreamFusion工作使用的Mesh+Texture的结构,反映到人体,人体模型的3d生成也是一个常见方向
人体
一种分类是
身体、头部、头发和手部
对于身体又可以进一步分为full body modeling,同时按训练来源可以分为多角度视频和单目视频,
我目前计划的分类
mindmap
root((分类))
按部位分
人体整体
GSMs
头部
头发和手部
按目标分*有一点点不合适的就是几乎所有重建工作都有提到动画化
人体重建
多目重建:
ASH:特色是引入了通过UV参数化,将高斯椭球锚定到可变形的网格上,高斯椭球的参数可以在二维纹理空间中学习,从动作捕捉器获取的骨骼运动信息到动态化参数的高斯椭球的过程就被简化成了2维图像到2维图像的转换任务。
Animatable Gaussians:特色是首先从多角度的图片学习一个从SMPL模型衍生而来的参数化模板,并通过将模板正交投影到正面和背面两个视图来在二维空间中学习高斯椭球的参数化,这两个与姿势相关的参数化视图则通过styleUNet生成模型生成
单目重建:
GSMs:特色是引入了multi shell based scaffold, 通过styleGAN2生成shell map获得3DGS的属性,并针对头部、手部、足部提供专门的discrminater提高,同时3DGS提供的显示表征提供了便利的编辑,可以在多个实例之间互换服装
HUGS:特色是使用三平面表征,并通过MLP模型预测高斯椭球的性质和人体的LBS weight
GauHuman:(与HUGs比较起来说)特色是引入了两个MLP微调模型为SMPL模型的LBS权重和姿态参数进行微调而非直接使用MLP进行参数预测,同时通过引入KL散度等改进了prune/split/clone过程
GaussianAvatar:特色是通过将姿态动作和特征属性解耦为两个不同的特征向量,通过encoder和decoder架构获得标准空间下人体模型
动态人体*deformation
HUGS通过MLP预测LBS权重,再配合提供的Joint Configuration进行LBS变形可以实现全新动作的合成
GSMs通过首先变换shell map并查询高斯椭球在mesh中关联的顶点变换后的位置来完成变形
人体生成
ASH通过给定骨架姿态,变形人体模版,将相应高斯椭球锚定到变形模版的顶点上,并配合可动画化的纹理实现动作合成
我在想要不要把这些文章人体重建的过程大致抽象出来,因为他们都好像,但是又怕写错 :(
Week 8
3D高斯泼溅所带来的高速渲染和显示表征为人体重建、动画化、人体生成任务提供了实时渲染和进一步优化细节和运动控制的机会。使用3D高斯溅射作为3D人体相关任务的基元并学习得到的显示表征的人体相较于使用神经网络辐射场(NeRF)学习得到的隐式表征的人体在渲染速度和泛化性上都有巨大的提升。最近的工作主要聚焦于利用3D高斯泼溅来重建得到可以实时渲染的虚拟人体或头像等,同时实现更精确的动作控制和新动作的合成,此外3D高斯泼溅与生成模型结合,生成高质量的人体模型也取得了一些突破。
对于人体整体的重建,HuGS提出了基于多角度视频利用3D高斯泼溅生成人体的方法,同时提出了一个从粗到细的人体动画化过程,首先使用LBS合成新的人体动作,而对于动作变换中非线性的部分,比如松弛服装在运动中的变换,HuGS提出了一个浅层神经网络进行捕捉和局部的变形改善。
HUGS使用单目视频即可训练,并使用三平面特征来表征高斯,高斯的特征(这里有疑问!)由三个分别负责预测颜色与不透明度、位置和旋转参数、LBS权重的MLP神经网络预测得到,这种方式方式相较于直接参数化单个高斯能够更好的避免过拟合风险,提供了更好的泛化性,能更好的完成全新动作合成的任务。
GauHuman则使用MLP模型对SMPL中的LBS权重偏移进行预测,同时使用另一个MLP模型对姿态进行进一步细化,避免直接使用MLP模型预测LBS权重可能带来的时间开销和低质量渲染。同时GauHuman还通过引入KL散度和改进合并操作来改进3D gaussian splatting原本方法中的分裂、克隆、合并过程。
GaussianAvatar结合了动态外观网络和可优化张量,从给定的SMPL模型帧采样点的位置并据此通过一个姿态编码器获得姿态特征张量,另外提供一个可优化外观特征张量来学习人体的外貌特点,这两个特征向量通过一个高斯参数阶码器得到标准空间下高斯的各个参数。
3DGS-Avatar指出HUGS、GauHuman等方法虽然达成了高速的渲染,但为此牺牲了对服装随着不同姿态产生的非刚性变形的拟合。3DGS-Avatar将变形分为非刚性变形和刚性变形两步来完成,同时通过一个能够考虑到光照效应和局部变形的小型MLP网络解码颜色,从而在渲染速度和渲染质量之间达到较好的平衡。
为了解决直接从3D空间学习高斯参数带来的计算困扰,一些方法尝试将问题空间从3维投影到2维,以降低问题的复杂度,同时便于利用已经相对完善的二维网络进行参数学习。
(我不确定GSMs属不属于这一类,GSMs也是通过生成shell map来参数化高斯的,并且用的也是“适合2维空间的”CNN模型,不过GSMs的作者并没有提到这一点,不过看起来GSMs应该归到生成一类)
ASH提出首先通过一个变形网络生成一个与运动关联的模板网格,基于此预测和运动相关的纹理映射,生成的纹理映射通过位置阶码器和外观解码器为高斯提供参数,这样模型可以在纹理空间学习高斯的参数而不是在3D空间中直接学习。
类似的,Animatable Gaussians通过将标准空间当中的模板网格人体投影到人体正面和人体背面两个方向,从而在这两个2D空间中学习高斯参数。同时Animatable Gaussians提出利用主成分分析(PCA)将全新的姿态驱动信号投影到训练过的姿态空间中以获得针对新姿势生成的更好泛化性。
除了人体整体的重建和动画化,3DGS为人体头部的重建与动画化也带来了较大的进展,GaussianAvatars通过将FLAME网格和高斯泼溅结合来取得更好的渲染效果,高斯泼溅的主要用途是对FLAME网格无法精确描绘的细节或没有跟踪的元素进行补偿。初始化时FLAME网格上的每一个三角形都被放置一个高斯,并在训练过程中进行优化,同时为了在自适应密度控制中保持可控性,GaussianAvatars通过独特的继承机制确保每一个高斯都与FLAME网格中的一个三角形相关联,当对FLAME网格进行动画化时,每一个高斯也相应做出变形。
GaussianAvatars虽然取得了很好的重构效果和动画化,但是训练时并没有和照明信息解耦,Relightable Gaussian Codec Avatars(这篇工作感觉涉及到比较晦涩的关于球谐函数和球谐光照的知识,我感觉我一下子搞不定:()。
Gaussian Head Avatar指出直接使用FLAME网格和LBS进行面部变形这种相对简单的线性操作很难表征精细的面部表情,相对的,Gaussian Head Avatar提出使用一个MLP网络直接通过输入表情相关参数来预测高斯在从中性表情到目标表情之间的位移来实现高达2K分辨率的头部图像渲染。
在人体生成方面,
Gaussian Shell Maps(GSMs)则通过壳式结构结合了CNN生成模型和3D高斯泼溅,一系列壳式网格基于SMPL模型适当的膨胀或收缩,CNN生成模型为这些壳式网格生成纹理映射,这些纹理信息进一步确定了锚定到网格上的高斯的属性。这种壳式表征可以更好的表示SMPL模型中不包含的服装、头发等特征。同时高斯泼溅的显式表示和壳式结构层次性的表征为编辑人体提供了很大的便利,可以很方便的交换生成模型之间不同壳的属性,实现为人体模型更换发型和服装的需求。
Week9
| Task | Achievements |
|---|---|
| 复现3dgs | 目前已经跑通,在进行code review,因为我本身pytorch基础很差,所以得边看边学 |
| generative model | 学习transformer架构 |
| few-shot reconstruction | |
| 综述 | 补齐另外两篇综述中 |
单词向量空间
应该是是最直接,最古早的文本编码思想了
基本想法是给定一个文本,用一个向量表示该文本的“语义”,向量的每一维对应一个单词,其数值为该单词在该文本中出现的频数或权值
基本假设是文本中所有单词的出现情况表示了文本的语义内容
我们的基本空间是全体文本
最早常用的权值叫 单词频率-逆文本频率
其中单词频率指这个单词在目标文本中的频率,即
逆文本频率指的是这个单词在全部文本的多少篇文本中出现过的倒数取log
即这个单词越是只在这个文本中出现,就越能代表这个文本,自然重要度也就越高
乘起来就是
度量两个文本的相似度可以用余弦
word embedding
如果我们有10000个单词,我们可能会想用一个长度10000的向量来表示单词,只要是哪个单词对应的编号就位1,其他为全0
但是这样我们无法得到各个单词之间的相关性,我们希望能有一种无监督的方法,自然地帮助我们找到单词之间的关系
两种很棒的无监督方式是
- 聚类式
- 生成对抗式
word embedding更类似于后者
我们可以训练一个函数
这个结构就好像:
输入是one-hot编码的单词,一个神经网络将one-hot单词编码到隐藏维度,隐藏维度接上softmax就是每个单词出现在下一个的概率
因为one-hot就是只有一个维度为1的向量,所以相当于选出了隐藏层权重矩阵的一行,也就是隐藏层的权重矩阵就是我们的wordvec单词表了!假设我们有十亿个单词,隐藏层的维度是300,我们就相当于将十亿维的one-hot表示压缩成了300词向量表示,而且还获得了语义信息。
position embedding
Sparse reconstruction (Few-shot) & 3DGS
Encoder-Decoder style
感觉主要利用Decoder提供的先验知识进行单图重建
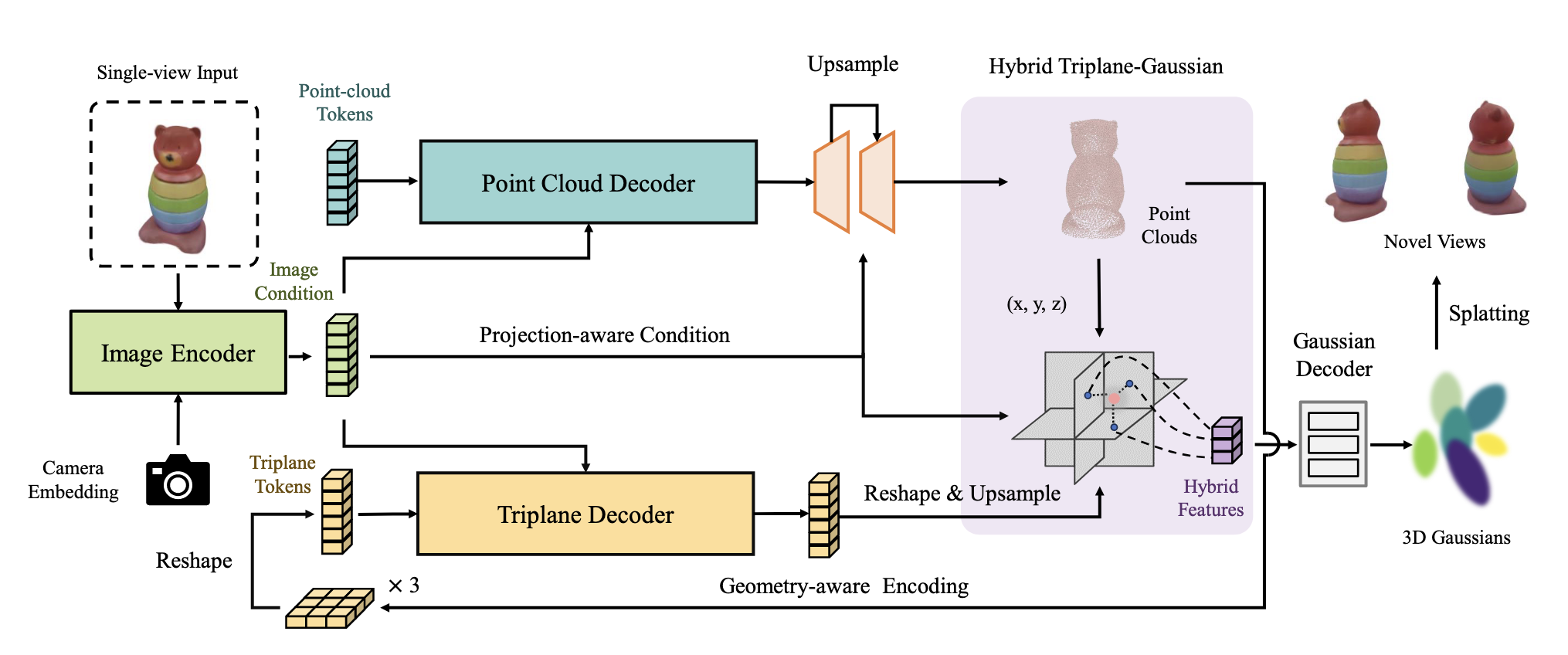
一个点云decoder预测basic point cloud,一个triplane decoder预测高斯属性
Predicting Supervise Information
感觉主要利用depth model提供的深度先验知识
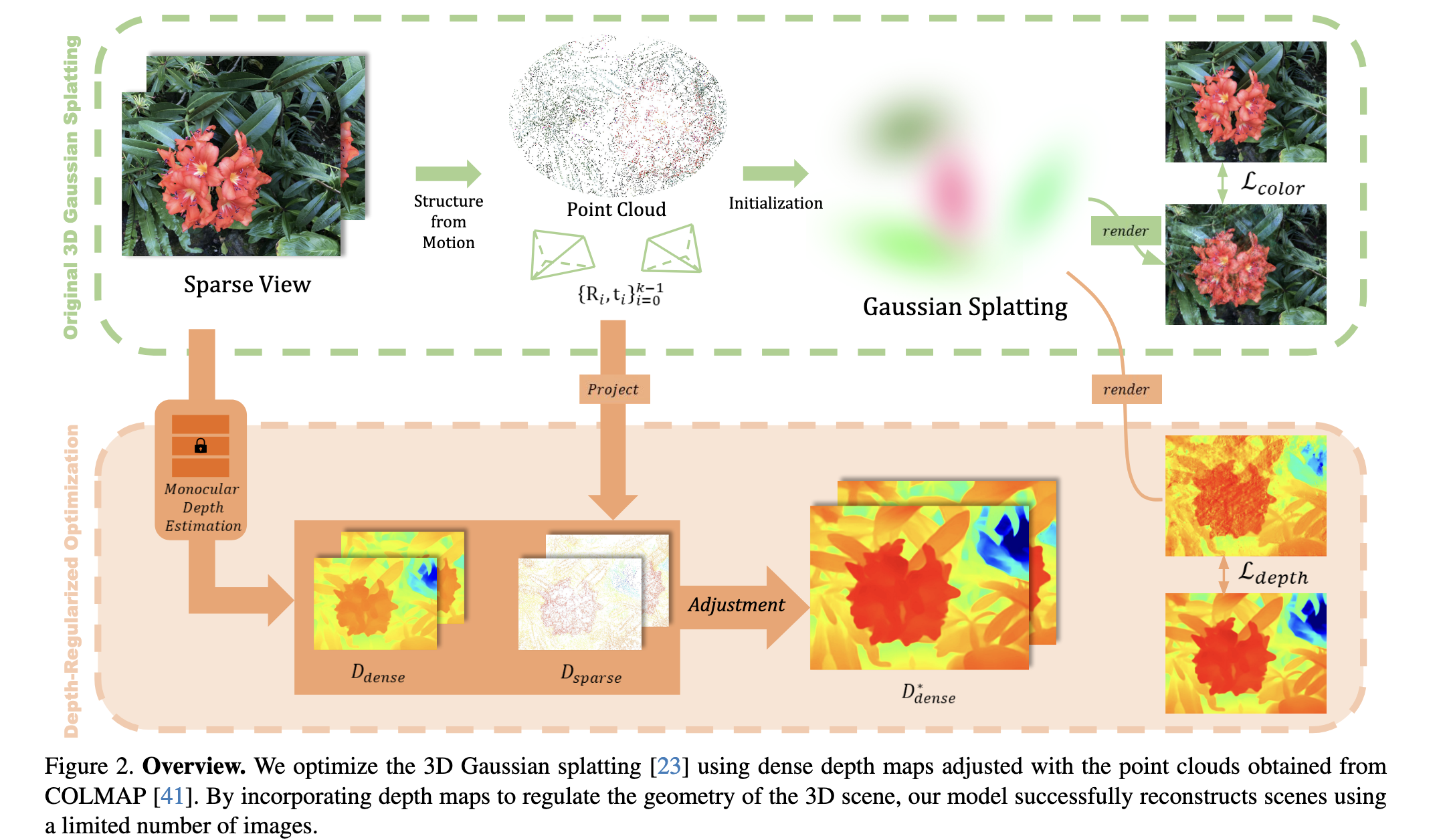
Generative & GAN style
主要利用生成模型来“想象”这个输入在其他视角下是什么样子的,从而实现数据增量
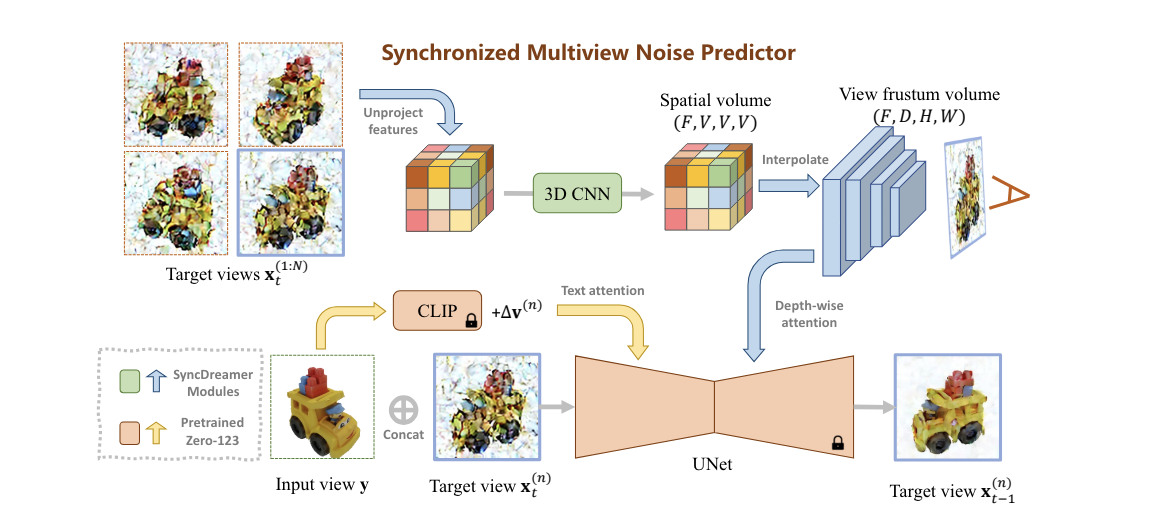
Week 10
| Task | Achievements |
|---|---|
| 复现3dgs | 目前已经跑通,在进行code review,因为我本身pytorch基础很差,所以得边看边学 |
| generative model | 学习transformer架构 |
| few-shot reconstruction | review cvpr 2020 best paper |
| 综述 | 整理综述,列出重要方法 |
Gaussian Shadow Casting for Neural Characters
这是我目前看得比较莫名奇妙的文章,这篇文章首先把训练视频经过NeRF得到一张密度分布图,将密度分布图转换成人体高斯集合,并提出一种针对高斯集合的光线追踪法,基于此计算人体的阴影
我不能理解的就是为啥他非要通过nerf输出的密度分布图来重建高斯图呢?用smpl模型初始化然后通过学习一个pose,调整好pose以后将smpl模型转换成高斯不是更爽么,还是因为那个nerf模型能够顺便帮他把法线和反照率预测出来而原本的高斯方法不行所以他才一定要用nerf呢?
cvpr 2020 best paper:Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
这篇工作将“对称性”这个先验用得很妙
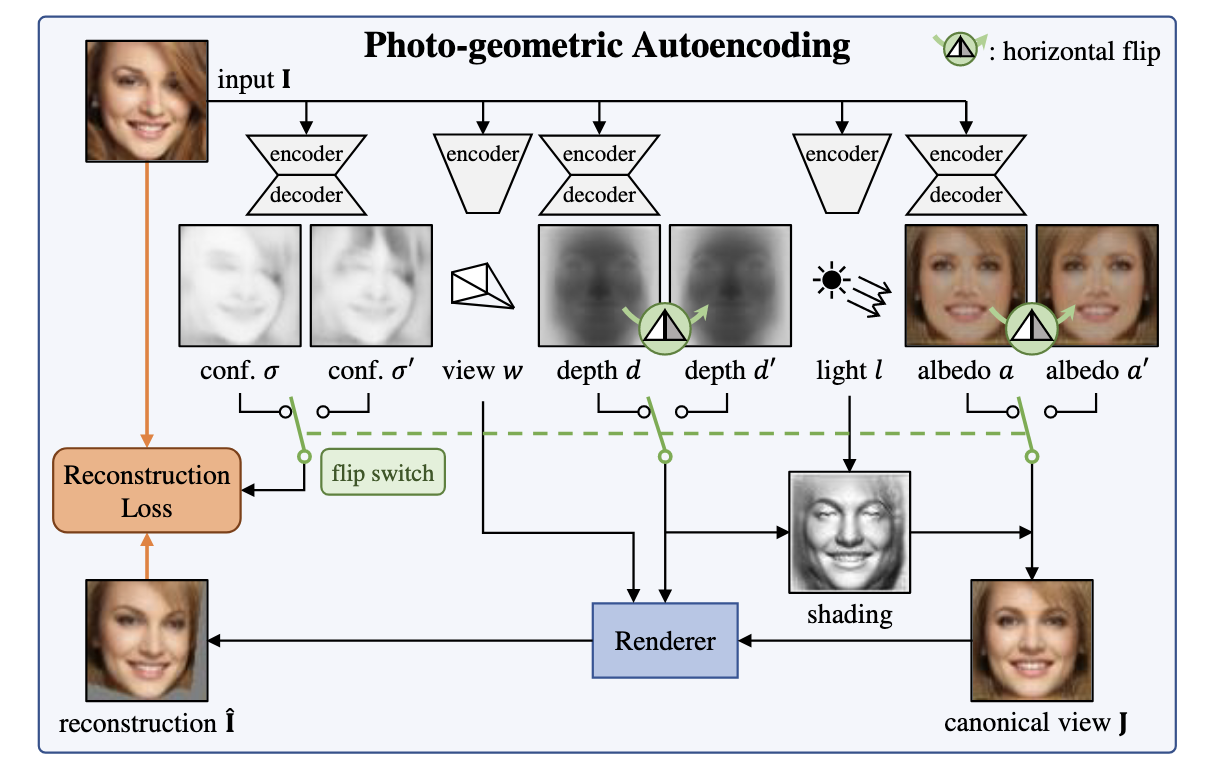
重建一个物体,需要深度和反照率,
这篇工作提出了一个pipeline,首先判断一张照片中,有哪些像素可能是3D空间中的对称关系,而这些有对称关系的像素,他们的反照率和深度信息应当是相近的,而非对称像素不受这个约束,于是损失就成为了: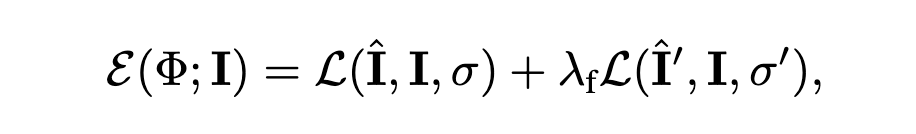
其中
1 | 2 4 |
Week 11
这周主要是进一步了解Encoder-Decoder style的泛化性工作,我重点选择了
AGG: Amortized Generative 3D Gaussians for Single Image to 3D和Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers这两篇文章
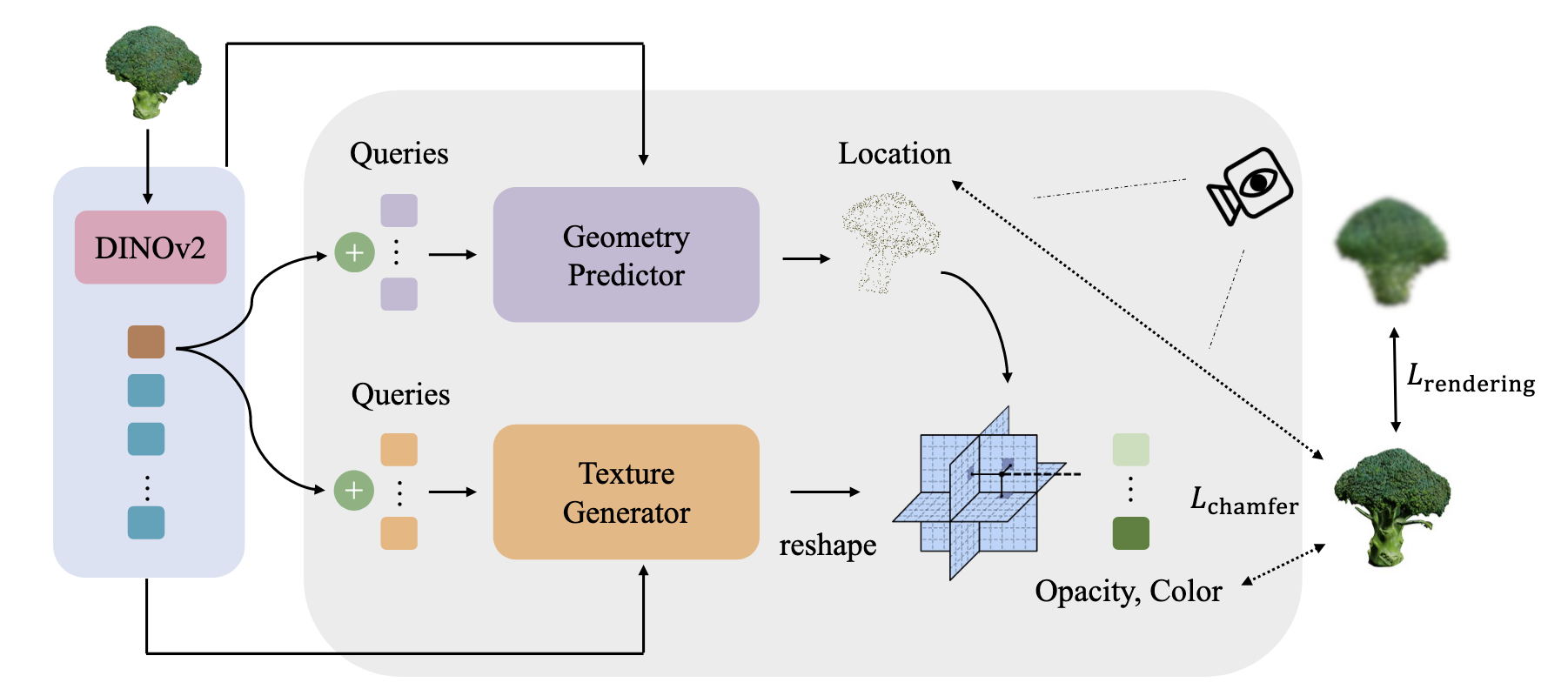
两种方法都使用了混合式的中间表征来对物体的形状和纹理分别表示和重建,triplaneMeetsGaussian额外引入了triplane的隐式表示来增强泛化性,针对triplane再提供一层decoder预测高斯属性,避免直接使用decoder预测高斯属性时导致的问题。
两篇文章都使用transformer进行encoder和decoder的设计,我在想encoder和decoder的训练过程是否有可能改进
- 文本监督 文本+图像 one-shot 调研风险
- MAMBA 目前还没有看到 mamba的引入 效果堪忧
Week 12
这周主要在进行综述文章的翻译和补充工作,我之前还没有写过英文论文,因此进度比之前用中文缓了一些,争取周三完成我的部分
关于文本监督引入图像重建的可能性
调研上我目前还没有看到关于文本和图像作为联合输入进行重建的文章
学长说这可能是一个应用点,但是最大的问题在于数据集上,很多时候可能需要使用CLIP来标注图片,这样数据的质量就堪忧了
MAMBA的引入
和学长进行了交流,学长说他已经就mamba替换transformer做过尝试,发现训练效率有比较大的下降,风险比较大
Week 13
按照身体部位来给人体重建的文章分类未免也太蠢了,我打算试试按照技术分类,这样显得更聪明,但也有风险,作为一个菜鸟,我很担心我对这些技术的理解有偏差呢
| Research | pose-dependent non-rigid deformation | novel pose animation | fast training | high frame rate real-time rendering(>60FPS) | monocular input | Super-resolution |
|---|---|---|---|---|---|---|
| HuGS | Yes | Yes | No | No | No | No |
| *GPS-Gaussian | - (No need) | No | - (Don’t need per-object optimization) | Yes | No?(虽然是360度拍了照片,但是好像只选了其中相邻的两张?) | Yes |
| HUGS | No | Yes | Yes | Yes | Yes | No |
| GaussianAvatar | Yes | Yes | Yes *0.5-6h single 3090 | Yes | Yes | No |
| GauHuman | No | No | Yes | Yes | Yes | No |
| 3DGS-Avatar | Yes | Yes | Yes | No | Yes | No |
| ASH | Yes?(“motion-aware appearances” ) | Yes | 作者没说,我来训一遍 | No | Yes | No |
| Animatable Guassian | Yes | Yes | No | No | No | No |
*GPS-Gaussian等不使用SMPL模型的方法或许不能在此之列,因为他们行事不必受到SMPL模型的限制
未来可能的方向:
引入关于服装的物理先验知识来辅助完成服装被动画化时的变形
Week 14
泛化性生成
泛化性网络 2d视频->6d xyz+t
聚焦泛化性 (gaussian,带有生成性质的不是重点)
同时用服务器复现代码,形成统一认识
泛化性方向gaussian可能没有效果好,泛化性下大家不看时间看精度
dynamic 先不用看,先看泛化性
nerf 4d泛化复现
泛化性高斯+综述 ppt记录 新文章 复现开源文章
| 任务 | 进展 |
|---|---|
| 泛化性的复现 | 复现MVSplat |
| 动画化的学习 | |
目前主要的任务
我目前聚焦泛化性,主要对MVSplat和pixelSplat进行复现
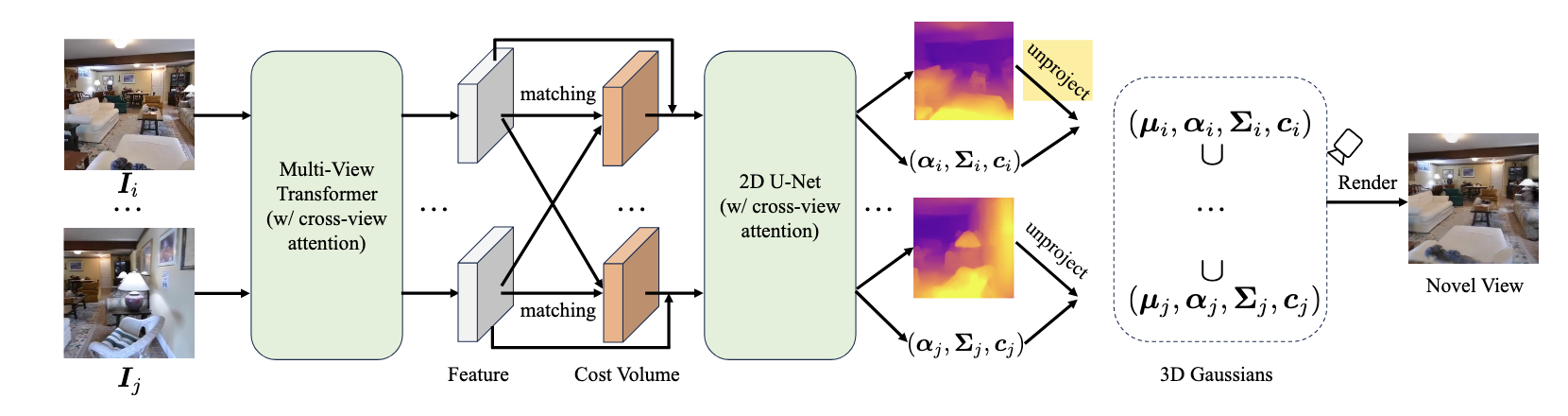
而这整体的pipeline是相似的,MVSplat使用Multi-view transformer获得基于单目视频上下文相关的feature,通过cost volume存储监督信息,并查询,最后通过Unet获得高斯元的具体参数,这里方法的最大特点是十分依赖初始化,由于gaussian splatting 中的clone和purne过程不是直接可微的,所以往往初始化后点的数量是固定的,实际上很难出现巨大的改变。
+放出来结果
Week 18
MonoNerf
| 论文 | 目的 |
|---|---|
| Attention is all you need | 了解transformer架构 |
| Self-Calibrating 4D Novel View Synthesis from Monocular Videos Using Gaussian Splatting | 与目标工作相近 |
| Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models | 4d生成 |
| 3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting | 这里面Non-rigid Module有些没看懂,得问一问 |
| A taxonomy and evaluation of dense two-frame stereo correspondence algorithms | 了解cost volume流程 |
复现结果
明确量化结果
pipeline

迁移计划
如何使用光流对高斯进行监督
泛化性(学长的意思是不再按照mvsplat的流程来做,主要原因是使用的人太多,并且渲染速度(训练速度?)比较慢)

目前此领域相近的文章
Self-Calibrating 4D Novel View Synthesis from Monocular Videos Using Gaussian Splatting

代码
暑期week1
| date | paper | code |
|---|---|---|
| 7.12 | Self-Calibrating 4D Novel View Synthesis from Monocular Videos Using Gaussian Splatting | |
| 7.13 | ||
再check一遍
按motivation分类
小技术 trick写在中文里面标红 要写得详细一点(一到两句话)
列出比较表格
github列表
1 | \begin{table*}[ht] |
暑期 Week1
| date | task | detail |
|---|---|---|
| Survey | https://github.com/qqqqqqy0227/awesome-3DGS | |
| Code | resnet | |
| Code | Mononerf 准备和学长一起搭建baseline |
Summer Week 2
对self-distilation的探索
ablation experiement on attention(resnet50)
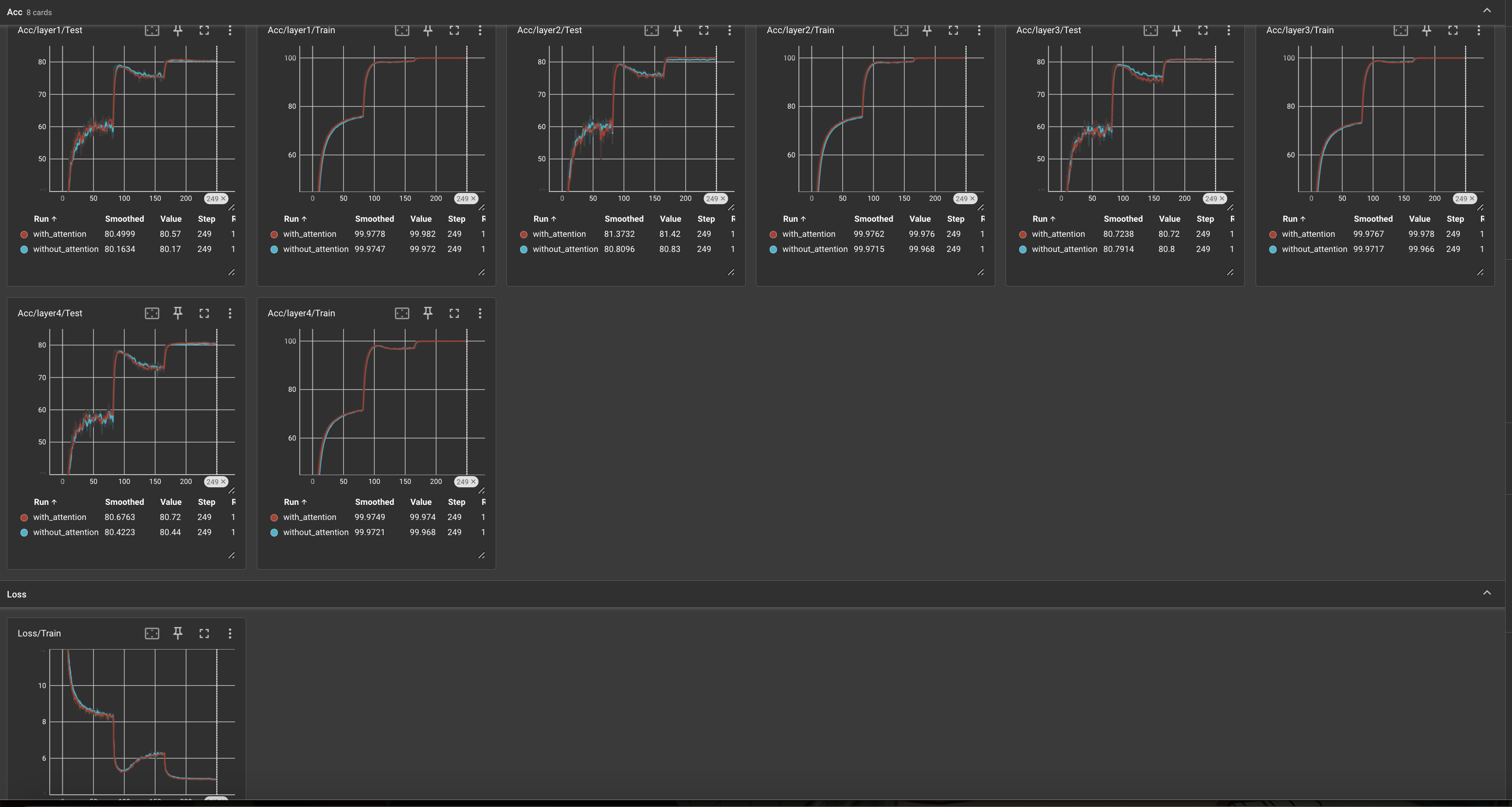
红色的线是有attention层,蓝色的线是去掉了attention,两条线几乎重合,我觉得至少在resnet50上,attention层的效果似乎不显著
小模型的另一种实现方式 Model Quantization
Paper:AdaRound
这篇文章从rounding后模型误差的二阶泰勒展开式出发,在做了一些让我有些看不明白的假设后,得出了非常直观的结论:
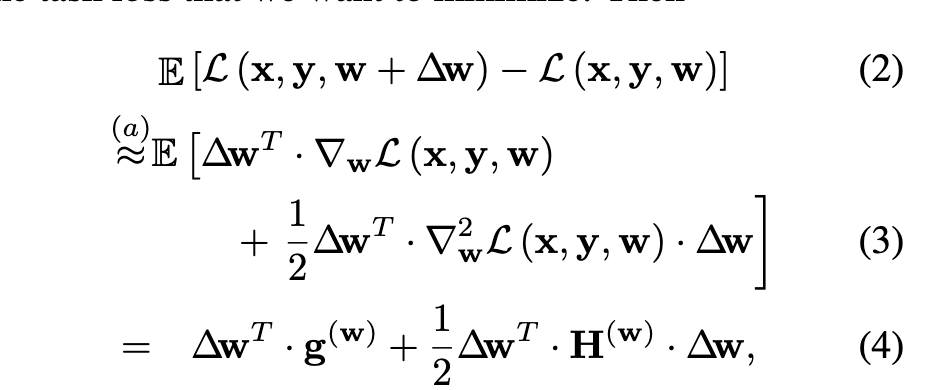
假设一:gw=0,因为假定模型已经是收敛的,因此一级梯度确实应该是趋于0
所以问题退化成求公式(4)后边部分期望的最小值
展开海森矩阵
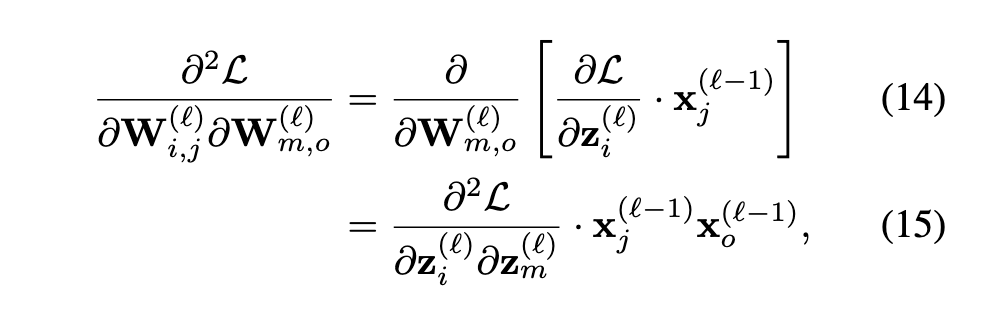
可以写成如下形式
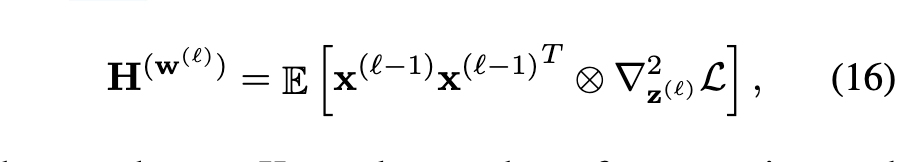
假设二:
Loss对zi偏导后,结果不会在包含zj(我感觉就像是传播到zi的损失不会受zj影响),这一步好像也能理解,因为一些常见的层比如卷积层、全连接层,确实zi zj之间一般是通过加减之类的运算传递到结果中去的,导一次就解耦了,但是如果算上其他层的我就有些不理解了,比如:

经过这样的假设,就成了对角矩阵
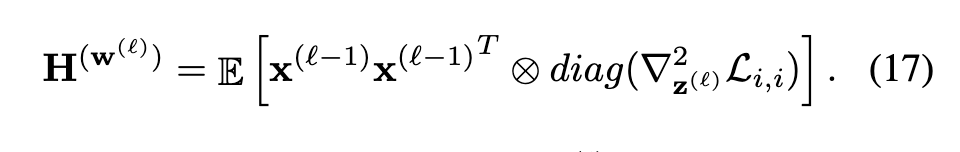
接下来代入式13
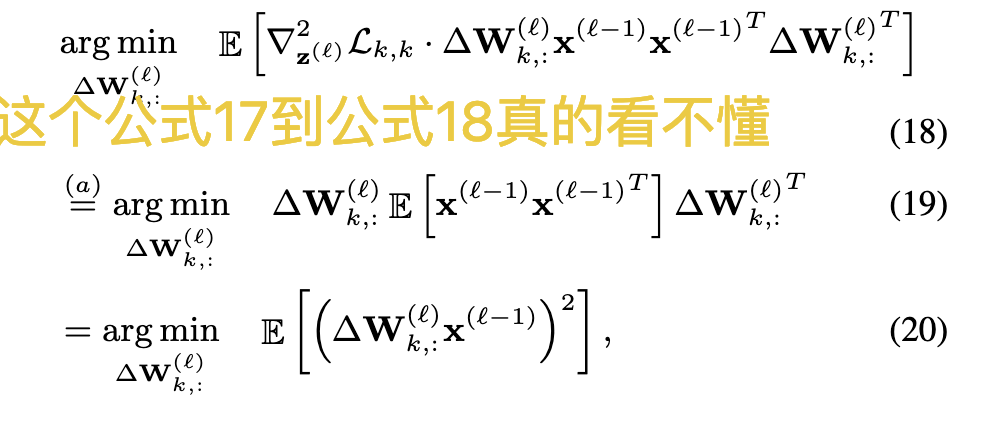
假设三:
假设上面的对角矩阵里面的每一个对角线值,也就是L对z的二阶偏导,都是固定的常数(这个操作已经看不懂了)
最后得到了非常符合直觉的式20——要让式13最小,(经过一系列假设后,)等价于让第l层的输入xl-1和round带来的权重变化之积最小,这个做法很类似resnet要求第l层除了能拟合f(x),还要能拟合x本身
(这个结果直觉到我在想他到底是推导得到了这个结论,还是从这个结论出发,反补出了一段证明)
有疑惑的一个操作:

假设三的负面影响实在是太大,为了平衡这种影响,他们加了一个激活函数fa,我不理解为什么一个激活函数能平衡掉这种影响。
However, this does not account for the quantization error introduced due to the previous layers. In order to avoid the accumulation of quantization error for deeper networks as well as to account for the activation function, we use the following asymmetric reconstruction formulation,where xˆ is the layer’s input with all preceding layers quantized and fa is the activation function.
Summer Week 3
self-distillation的后续(
因为实在没想法决定骚扰一下作者!
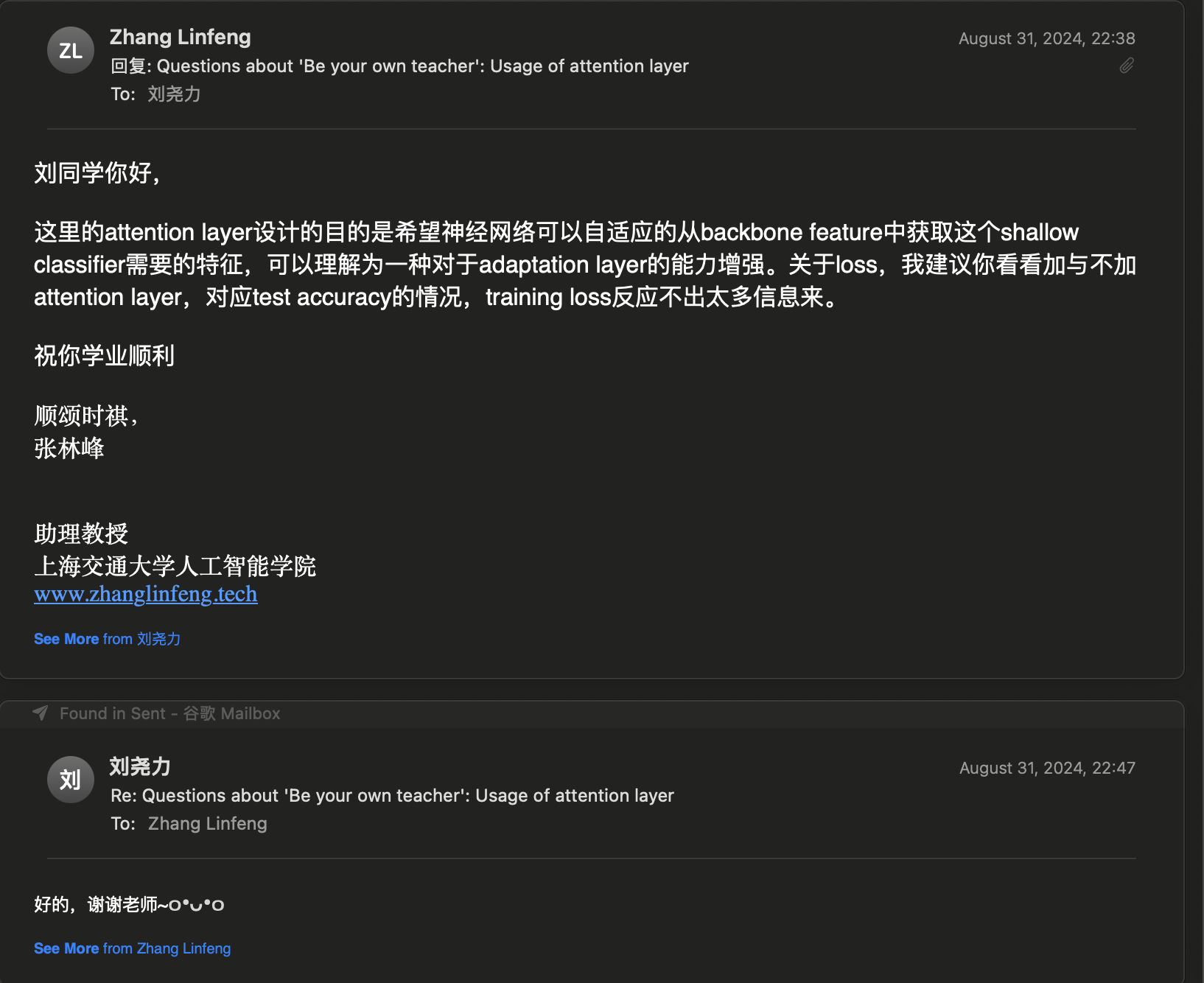
从回复来看Attention确实应该就是起一个补足adaption layer的作用,我想有它没它似乎影响都不大,也许有能带来一些超参数化的福利吧
了解Transformer
之前一直自以为已经了解transformer了,看了一下code发现还差得远,所以开始先从Attention is All You Need的实现开始过一遍Transformer的实现,目前才刚刚实现完Multi-head Attention:(
Attention 的思想机理是希望求出一个权重,这个权重昭示着一个序列中的某个元素对于序列中另一个元素的“注意力”,对于每两个元素都做这件事情,我们就得到一个权重矩阵
以AAYN中的实现为例,作为一个翻译模型,模型将输入序列
那么输出
而像GPT-2这样的模型,其目的在于文字接龙,采用的是Transformer decoder架构,因此它其实是一个递归函数
输出
上面描述只考虑了Attention 层,实际的实现还加了一些其他的层呢,我慢慢来好咯
Attention Mechanism
朴素的Attention
我们定义一种最简单的QKV配对机制,简单到QKV就是
那么我们可以得到权重矩阵
这种表示最大的问题是权重矩阵
QKV参数化
为此,我们需要将QKV参数化,方法非常简单,我们把
还有一个讨嫌的问题是——为啥要用Multi-Head?
首先我们要明确Single-Head和Multi-Head的差别到底在哪里,首先我们假设一个single head,它的QKV矩阵对应的隐层维度为hidden_dim,记作h, 输入维度为embed_dim,记作e,那么一层attention做的事情是这样的,其中QKV大小都是(h, e),X的大小是(e, seq_len),Q’K’V’的大小为(h, seq_len):
现在我们将它分成m个head,那么每个head的QKV隐层维度为h/m,一层Attention做的事情是这样的
$$Q’1 = Q_1X + b{q1},\ Q’2 = Q_2X + b{q2},\ …\ Q’m = Q_nX + b{qn}
我们会发现其实二者的前三步没有区别,将multi head的每个QKV concat起来就会得到single head的计算结果
真正的区别是在计算权重时产生的,single head使用了一整个Q’和一整个K’生成了一个(seq_len, seq_len)大小的权重矩阵,而multi head将Q’和K’沿着hidden_dim分别砍成了m份,每份组合起来分别生成了m个(seq_len, seq_len)大小的权重矩阵,最后分别和(h/m, seq_len)的
所以最大的差别在于multi-head可以针对V’的每m个维度,分别学习一个独立的权重矩阵,为什么要这么多独立的权重矩阵???
这个教程给出的解释是,我们希望模型从不同的角度去抽取W,比如对于”This restaurant is not too terrible”这句话,not、too这样的词语对于terrible是一种意义增强或者取反的关系,而restaurant和terrible是一种被形容和形容的关系,这种关系是完全不同的,对于这种关系上的本质区别,我们如果只有一个权重矩阵,很难衡量这三个词对于terrible孰轻孰重,但是如果我们有两个权重矩阵,一个衡量词义强度关系,一个衡量形容与被形容关系,V’也被分成两个部分,前一半维度用来描述词义强度,后一半维度用来描述词性强度,相应的K’Q’也被这样拆分,那么问题就能解决了,当然这只是一个简单的例子,模型真正学到的关系人类是很难看懂,但至少我们给了模型机会来从多个不同的角度形成不同的注意力。
另一种小模型可能的实现方式:Kans带来的参数压缩
先试着将目前流行的小模型方案都过一过
这个部分才刚刚开始看,我需要先能弄懂Kolmogorov-Arnold表示定理才行…
Summer Week4
Transformer
MoE
在实现Feed-forward的时候知乎推给我“为什么attention机制总是被魔改,FFN却几乎不变?评论区有人反驳MoE就是改变Feed-forward的典范,正好我在思考如何通过简单的门控更改transformer的推理过程,因此对MoE做了一点简单的了解,看了一份sample code,但是还没有看论文,需要了解MoE为什么topk选择多个专家能这么成功”
Xavier Initialization
Just one small problem: Why am I wanting the input variance equal to output variance? You may find answer here: https://zhuanlan.zhihu.com/p/428411878
self-distillation + transformer
将self dist迁移到transformer可能有这些问题:
- scala net占的参数量也太大了,比如我要为每一个encoder layer补齐scala net,除了补齐encoder,每个layer还要我补齐decoder,那也太巨量了
- encoder output在AAYN这篇论文里很重要,每个decoder层都要用它,是很重要的输出,那我是直接让每个encoder layer对齐这个encoder output(那这样就省了补齐decoder的巨大开销了),还是非要他们对齐最后的decoder
- …
Naive thoughts: Cycle attention
感觉总是ship别人的想法然后做迁移不太好,所以试着自己提出一些想法
想法根基:最近阅读了这样一篇文章Hallucination is Inevitable: An Innate Limitation of Large Language Models,文章的基本想法是,由于大模型本身能提供的计算复杂度和用户提出的问题被解决所需要的复杂度不一致(如用户提出的问题是NP难问题,但是大模型只是尝试用多项式复杂度的计算得出结果 我的理解可能不准确,这篇文章我才读到3.3节,需要继续读完)因此光从复杂度的角度来看,大模型就不可能得出这个问题的解
文章提了一些解决办法,比如更多的数据,大模型就可以进行查找而非计算,让解决问题本身需要的复杂度降低
还有早期流行的chain of thoughts,光从token数量来说,c-of-t就是增加了输出长度,而每输出一个token模型都需要计算,因此从复杂度的角度来看,这也是一种对复杂度的补齐
multi-agent让多个智能体相互协作,也付出了更多的计算代价。

那么可不可以直接让模型补齐这个推理复杂度呢?
我想设计这样一个模型

在推理时循环利用单个参数较大的A层,中间输出额外通过一个confident模块,这个模块进行简单的门控,决定模型当前有多大的信心可以输出结果,如果模型信心不足,就带着经过一定modify的latent再过一次A层,再进行判断,为了确保模型不会卡死自己,可能还需要一个罚时函数。
但是这个原始的想法可能有很多荒谬的问题
比如如果设A层是函数f,而confident带来的扰动又不足,最后可能就成了f(f(f(x)))…,往往会把模型导向一个不动点或者朝着单个方向爆炸
再比如对于f(f(f(f(x))))这样的操作,假设A层就是一个线性层,那么输出就是WWWWWx…这样最后如何更新损失呢?是每次过A都造成一次更新还是只更新一次呢?
再比如如果一个batch一个batch的training,每个batch的样本confident值都不一样,那有一些样本就要正式输出了,但是还有的样本需要继续过A,也会带来问题…
还需要继续思考…可能有一些实现可以参考,比如DiT模型将transformer应用在diffuse过程里,并在推理过程中不停地复用DiT(只是噪声程度在变),但是这个模型不需要自己决定是否要继续denoise,而且每次denoise都能产生一个可以直接反向传播的损失,所以参考价值可能也不是那么大…
KA Algorithm
推进比较慢,我需要先把丢掉的代数理论捡起来…
群
集合A上满足封闭性,结合律,单位元和逆元素的数学结构
阿贝尔群 交换群
满足交换律的群,还不如叫交换群,讨厌这些用人名命名的东西
域
在一个集合
两个运算之间有交换律
(令
那么
域有一些性质还没有弄明白,比如:域F中的所有非零元素的集合(一般记作F×)是一个关于乘法的阿贝尔群。F×的每个有限子群都是循环群。
域的扩张与闭包
希尔伯特第十三问:我们能找到高维多项式方程的根式解吗?
答:不能,从五次多项式方程开始,总是存在一个该次数的多项式方程,我们能找到它的一个解,而这个解不是根式形式
Proof 伽罗瓦理论
阿贝尔-鲁菲尼定理
五次及更高次的多项式方程没有一般的求根公式
域扩张理论
Summer Week 5
Transfomer
自己的transformer搓好了,但是在自己的电脑上跑了两天一个epoach还没跑完(希望后面能移到服务器上
要让服务器能访问huggingface真是一件头疼的事…
KA Algorithm
推进比较慢,我需要先把丢掉的代数理论捡起来…
群
集合A上满足封闭性,结合律,单位元和逆元素的数学结构
阿贝尔群 交换群
满足交换律的群,还不如叫交换群,讨厌这些用人名命名的东西
域
在一个集合
两个运算之间有交换律
(令
那么
域有一些性质还没有弄明白,比如:域F中的所有非零元素的集合(一般记作F×)是一个关于乘法的阿贝尔群。F×的每个有限子群都是循环群。
域的扩张与闭包
希尔伯特第十三问:我们能找到高维多项式方程的根式解吗?
答:不能,从五次多项式方程开始,总是存在一个该次数的多项式方程,我们能找到它的一个解,而这个解不是根式形式
Proof 伽罗瓦理论
阿贝尔-鲁菲尼定理
五次及更高次的多项式方程没有一般的求根公式
域扩张理论
Summer Week6
Cycled Attention
根据之前的探索,现有的模型架构的复杂度是
那么现有的模型应当不能拟合一个复杂度再
所以我们不妨定义这样一个数据集,这个数据集是直接从这个一个函数计算出来的:
定义这样一个运算
定义如下函数:
接下来我们定义这样一个序列生成方式:
即第k+1个元素是前k个元素通过对前k个元素的每一种排列应用函数
要计算这个元素我们要花费的复杂度是
recursive transformer recurrent transformer cot
Week 1
相似工作调研
我重点关注了相关文章中的下面这些问题
- 这个工作在循环生成时复用了那部分参数?
- 对于被复用的网络,在权重不变的情况下,什么东西影响了被复用网络的行为?
- 循环生成的停止条件是什么?
- 循环生成的中间产物是什么(也即每次被复用的网络收到的中间输入是什么)?
| 工作 | 复用部分 | 中间产物 | 影响复用网络的方式 | 停止条件 | 我的想法 |
|---|---|---|---|---|---|
| [1]SELF-REFINE: Iterative Refinement with Self-Feedback | 整个LLM | 人类语言 | 每次复用时,网络被告知对上一轮的输入做出评价,复用时,评价被用于引导新一轮的生成,从而实现refinement | 模型自己对每轮生成的结果生成一个评价分数,达到阈值时即停止 | 这个工作的出发点是认为多次prompt要求模型改进自己的生成结果可以不断提高生成的效果,这是符合直觉的。 这个工作的实现方式和我的想法有一些相似,但是主要区别在下面三点: 1. 中间产物是人类语言,每次模型都要将信息丰富的latent投影到人类语言再进行refinement,可能浪费了很多信息 2. 复用的是整个llm模型,而我希望复用几个特定的attention层 3. 这篇工作对于“何时停止循环生成”好像有点避重就轻,只是说可以让模型自己生成一些指标,而我希望可以思考有没有在latent空间借助门控之类的手段来进行控制 |
| [2]Recursive Transformer: A Novel Neural Architecture for Generalizable Mathematical Reasoning | 整个Transformer | 数学表达式 | 数学表达式会按照运算优先级被逐轮的简化,每次输入的表达式都有所不同 | 模型会在输出表达式时同时输出Continue或者stop token,代表目前是否还需要继续循环生成 | 这个工作的问题域是让LLM预测数学表达式结果 这个工作的分析过程和我的想法十分相似,比如一个数学表达式3*4+2*2,对于一个两层的transformer,第一层很可能就生成12+4,第二层再生成16,但是有些表达式非常复杂,这个过程无法完全进行,因此导致Transformer不能正确预测结果 这篇工作训练的方式也值得注意,对于数学表达式,构建一步步规约的数据集是相对容易的,因此所有的中间结果都可以得到直接强力的监督。 这篇工作随后探索了这样一种可能:能够不提供中间结果的监督,只有最后的答案 他们立刻就遇到了我同样遇到的问题: 由于不同的问题需要的步数不同,会为batch化的训练带来问题 同时如何保证全过程可微也需要仔细考虑 在他们终于用一些不太优雅的办法解决这些问题后,他们发现这样的模型相对于有强监督的模型至少有10%的精确度差距,这可能是一个可怕的警示,沿着这样的思路训练的模型可能很难收敛到好的效果上。 最后看了这篇文章真是羞愧难当,这不过是人家的一篇technical report就已经几乎把我目前的想法全部cover了,可见我目前的科研创新性还差得远。 |