单词向量空间
应该是是最直接,最古早的文本编码思想了
基本想法是给定一个文本,用一个向量表示该文本的“语义”,向量的每一维对应一个单词,其数值为该单词在该文本中出现的频数或权值
基本假设是文本中所有单词的出现情况表示了文本的语义内容
我们的基本空间是全体文本
最早常用的权值叫 单词频率-逆文本频率
其中单词频率指这个单词在目标文本中的频率,即
逆文本频率指的是这个单词在全部文本的多少篇文本中出现过的倒数取log
即这个单词越是只在这个文本中出现,就越能代表这个文本,自然重要度也就越高
乘起来就是
度量两个文本的相似度可以用余弦
word embedding
如果我们有10000个单词,我们可能会想用一个长度10000的向量来表示单词,只要是哪个单词对应的编号就位1,其他为全0
但是这样我们无法得到各个单词之间的相关性,我们希望能有一种无监督的方法,自然地帮助我们找到单词之间的关系
两种很棒的无监督方式是
- 聚类式
- 生成对抗式
word embedding更类似于后者
我们可以训练一个函数
这个结构就好像:
输入是one-hot编码的单词,一个神经网络将one-hot单词编码到隐藏维度,隐藏维度接上softmax就是每个单词出现在下一个的概率
因为one-hot就是只有一个维度为1的向量,所以相当于选出了隐藏层权重矩阵的一行,也就是隐藏层的权重矩阵就是我们的wordvec单词表了!假设我们有十亿个单词,隐藏层的维度是300,我们就相当于将十亿维的one-hot表示压缩成了300词向量表示,而且还获得了语义信息。
position embedding
Self-Attention的初衷
解决当输入是一个确定数量的向量集时使用
输入是向量
E.G NLP中将数据到向量
one-hot
假设所有词汇之间没有关系,没有任何语义信息
word-embedding
见上
输出有三种情况
输出是每个向量打一个标签
举例:词性标注
输出就是一个标签
举例:感情分析
输出是一个Sequence
就是我们最关注的Sequence2Sequence
如何考虑上下文信息?
最直接的想法是用滑动窗口,包住一定的上下文,但是输入是无限制的,所以不可能完全考虑
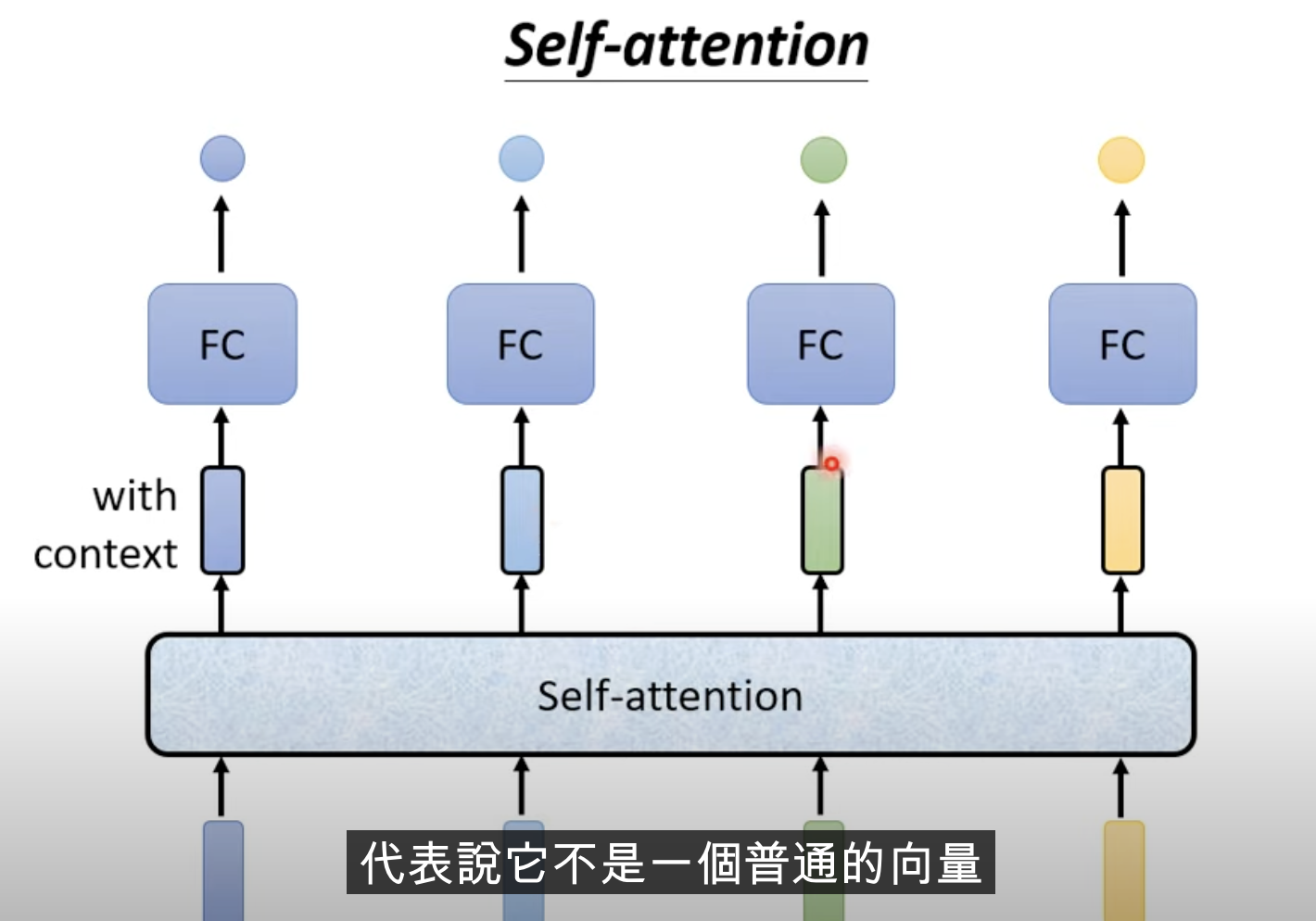
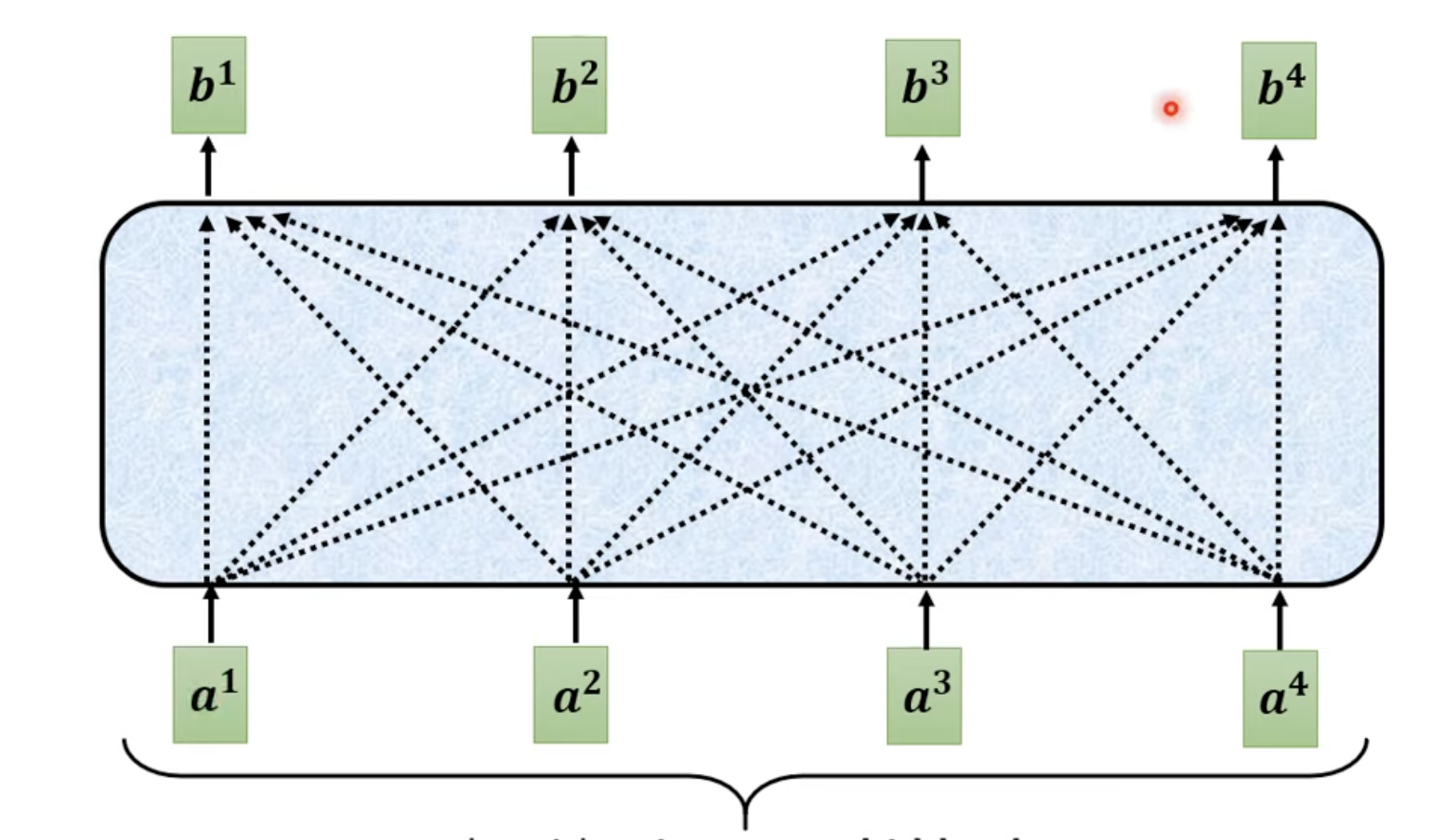
self-attention 输出和输入向量数量相同的向量,但是这些向量是考虑了全局信息的
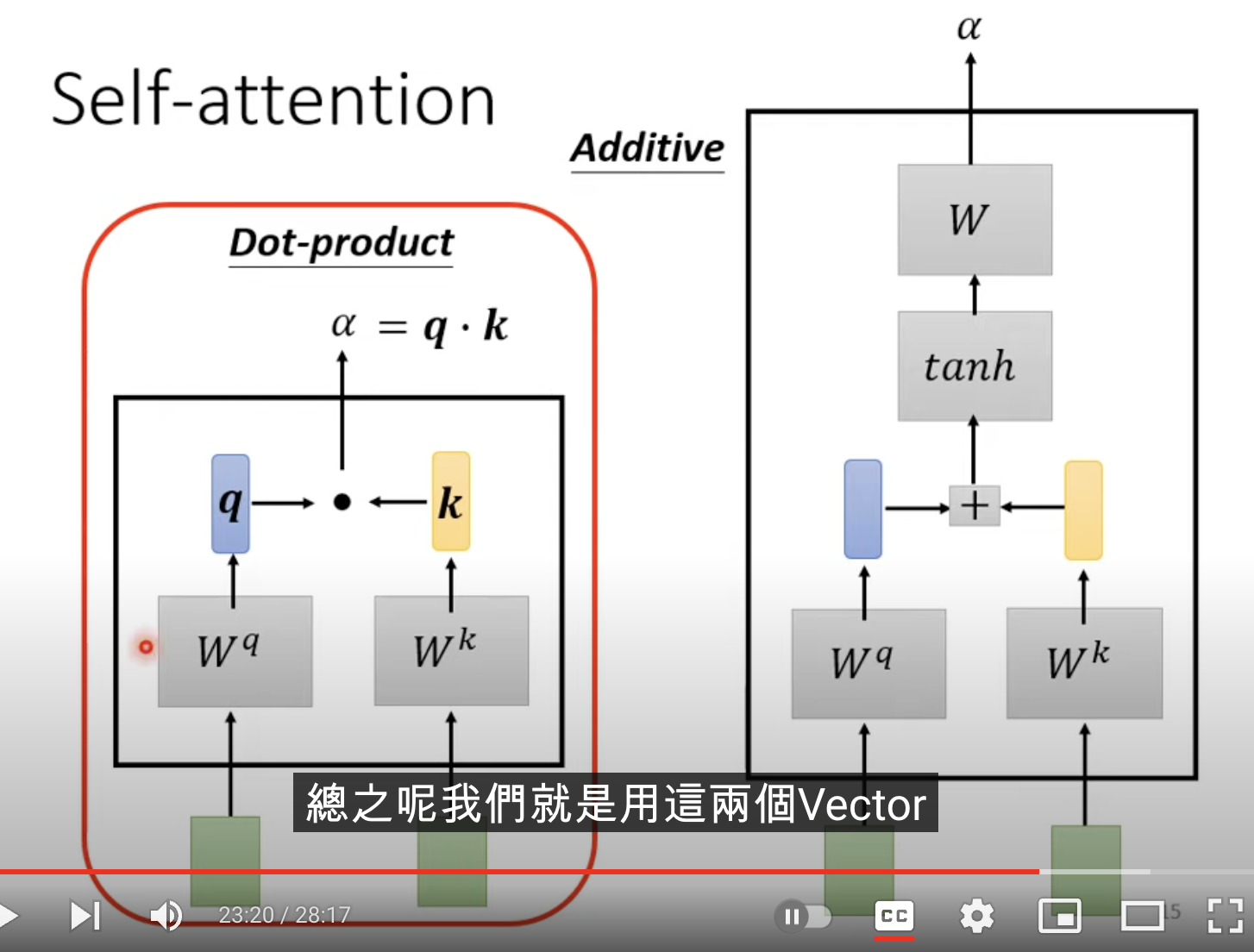
首先定义参数
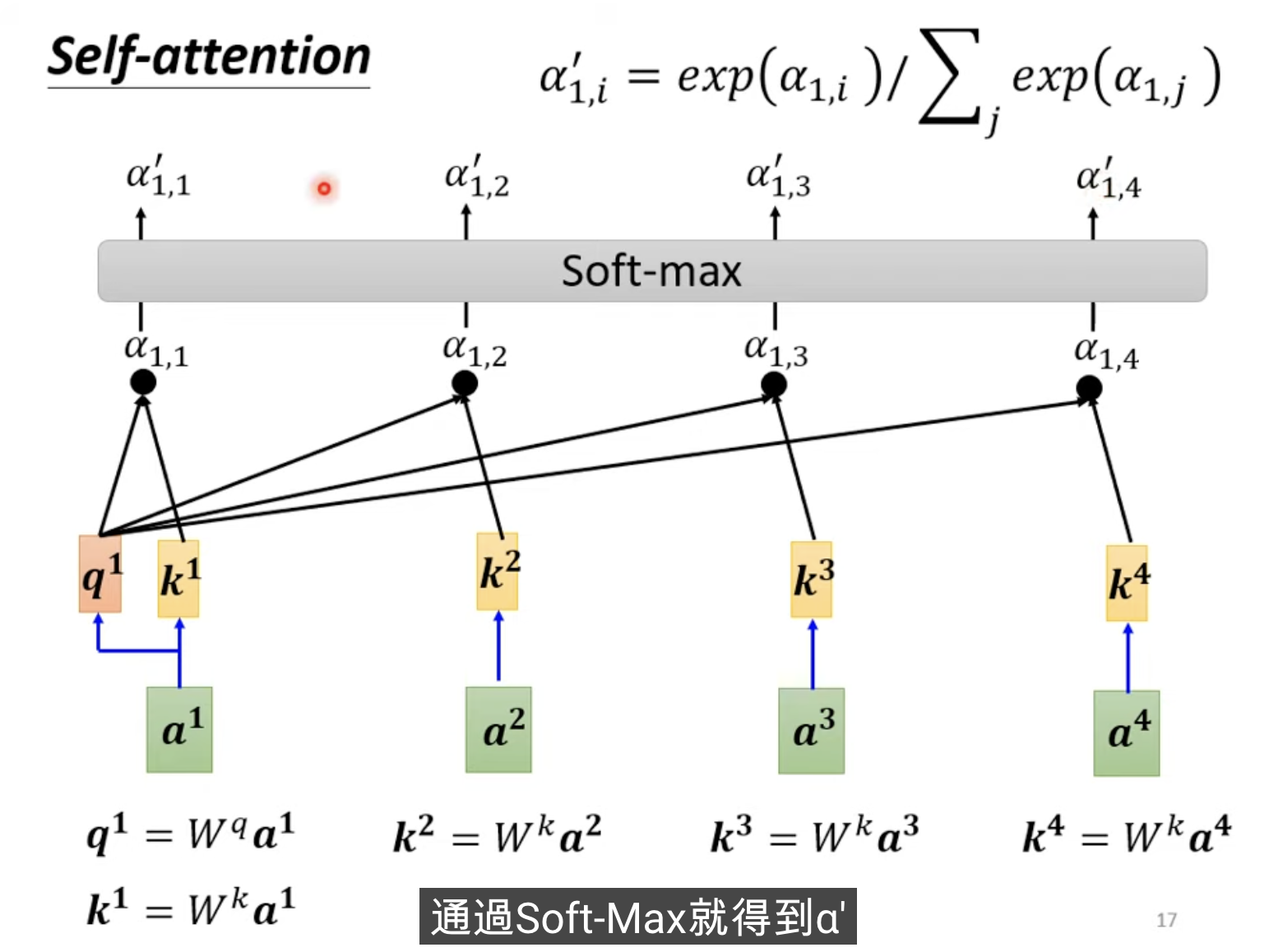
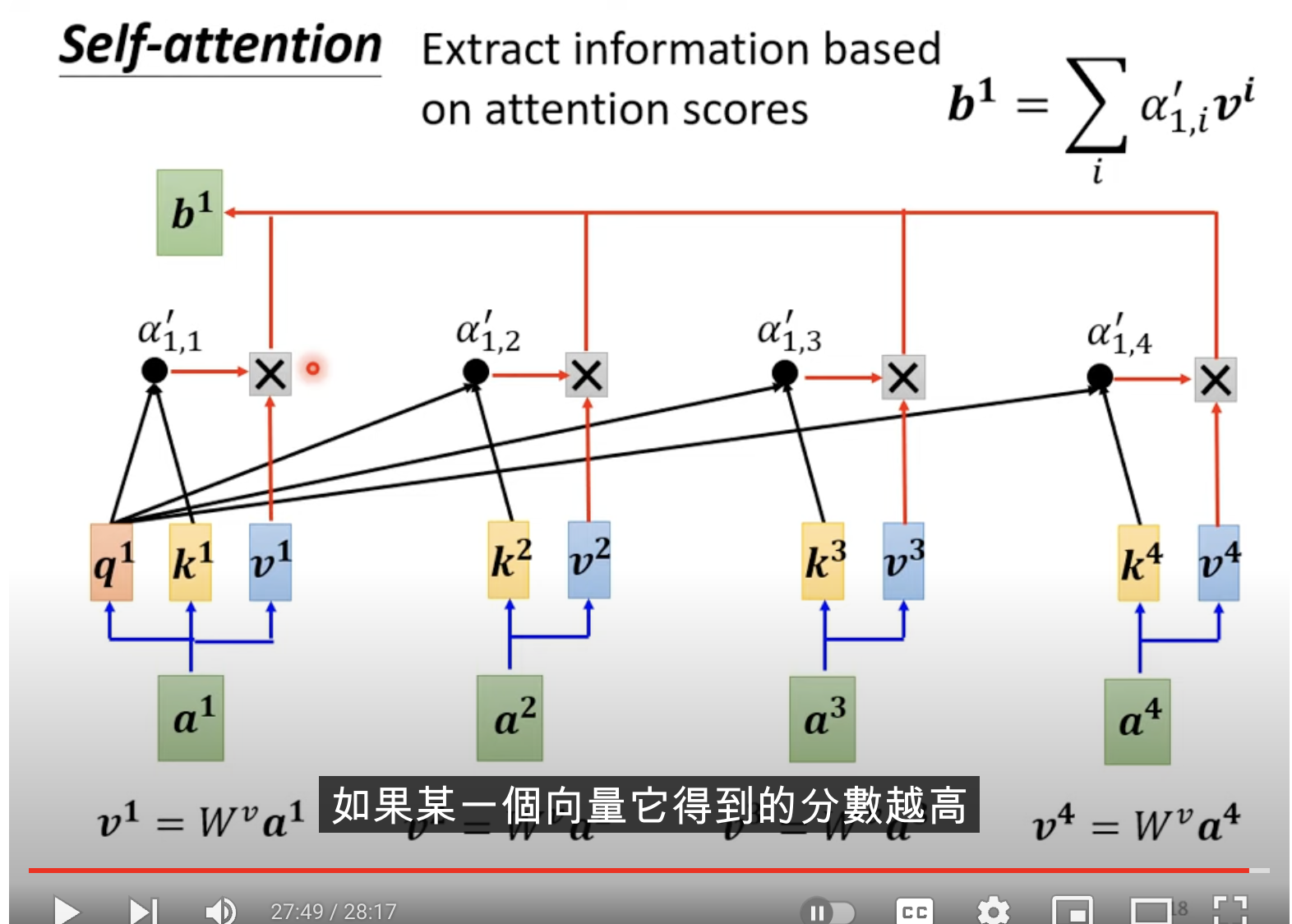
接下来我们需要借此获得上下文相关向量,我们再通过一个